Estructura de navegación
Tabla de contenidos
Paneles de Grafana
Qué son los dashboard
Un Dashboard es como el tablero de instrumentos de un coche, proporciona información sobre el funcionamiento del vehículo, como la velocidad, las RPM y el nivel de combustible. De manera similar, los paneles de Grafana son interfaces visuales que permiten monitorizar y comprender el estado de los sistemas e infraestructuras.
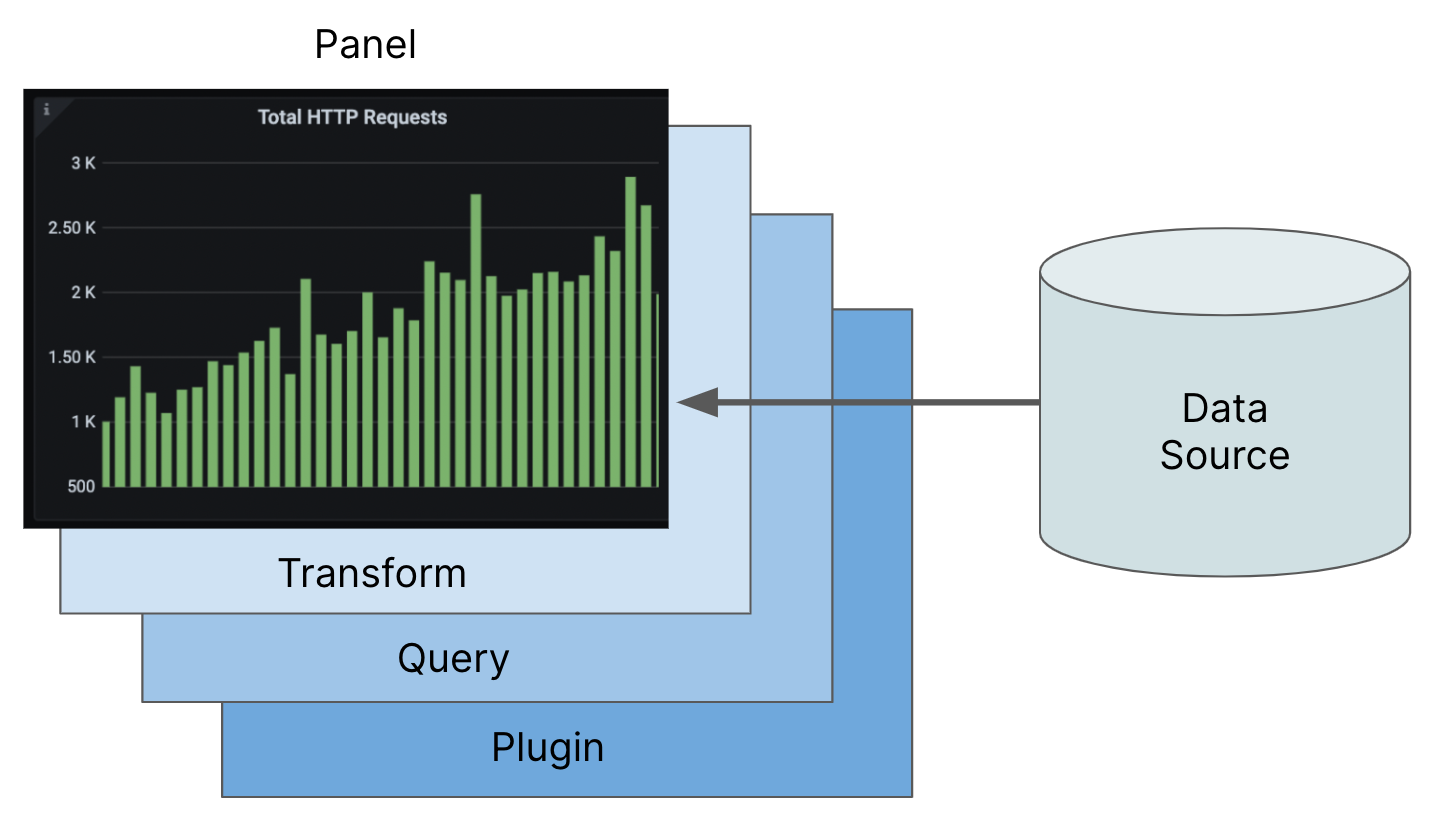
Los datos pasan por una serie de procesos para convertirse en un dashboard.
Fuente de datos: Extraemos los datos con los exporters para ser recolectados.
Plugins: Usamos el plugin de Prometheus para recolectar las métricas e introducirlas en Grafana.
Consultas: Permiten filtrar y reducir los datos a un conjunto específico, mostrando solo la información relevante.
Transformaciones: Manipulan los datos devueltos por una consulta para cambiar su formato o realizar operaciones adicionales. Son útiles para combinar campos, convertir tipos de datos o filtrar datos.
Dashboards: Paneles: Son los bloques de construcción básicos de un panel de control. Cada panel muestra datos en forma de gráficos, tablas o indicadores.
Creación del primer panel
Antes de empezar el primer panel tengo que explicar que hay 3 tipos principales de datos para trabajar con ellos:
Vector instantáneo (instant vector): Representa un conjunto de series temporales, cada una con un único valor para un momento específico en el tiempo. Suele utilizarse para consultas que obtienen el estado actual del sistema en un momento dado.
Vector de rango (range vector): Representa un conjunto de series temporales, cada una con varios valores medidos a lo largo de un intervalo de tiempo. Se utiliza para consultas que recuperan datos a lo largo de un período determinado, permitiendo analizar tendencias y patrones a lo largo del tiempo.
Escalar (scalar): Es un único valor numérico de punto flotante. Suele utilizarse para realizar cálculos matemáticos a partir de datos de series temporales o para representar valores agregados (por ejemplo, promedio, suma) a lo largo de un rango de tiempo.
He de añadir que existe un 4º tipo, que es el String, aunque este implementado no se utiliza actualmente.
Empezaremos creando, por ejemplo un panel para controlar el uso de la CPU:
windows_cpu_time_total
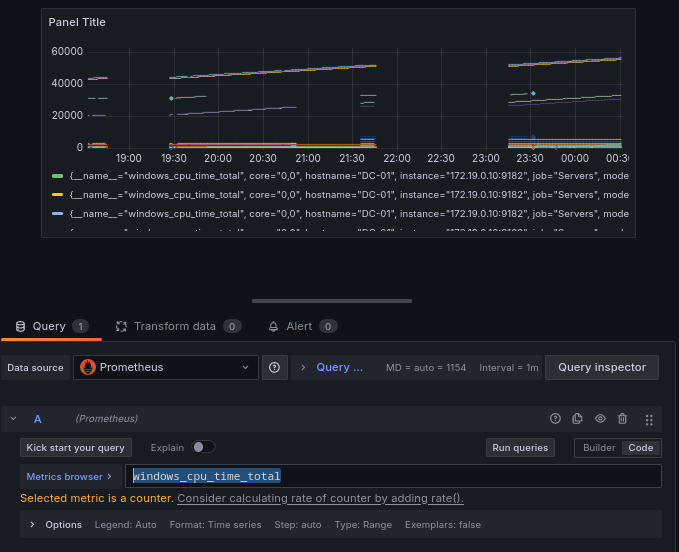
Con esa consulta nos da el tiempo de uso para la CPU, pero como no añadimos ningún filtro salen todos los datos de todos los equipos de los que obtenemos los datos, ahora filtraremos los datos para obtener sólo los del DC-01:
windows_cpu_time_total{hostname="DC-01"}
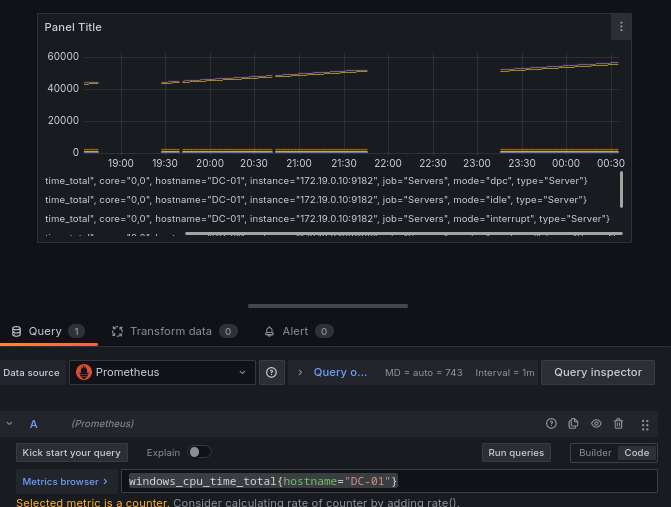
Ahora estamos filtrando los datos sólo para el DC-01, vamos a afinar un poco más para filtrar el modo que queremos obtener, ya que las CPU tienen varios modos, filtraremos por el modo de reposo o idle:
windows_cpu_time_total{hostname="DC-01",mode="idle"}
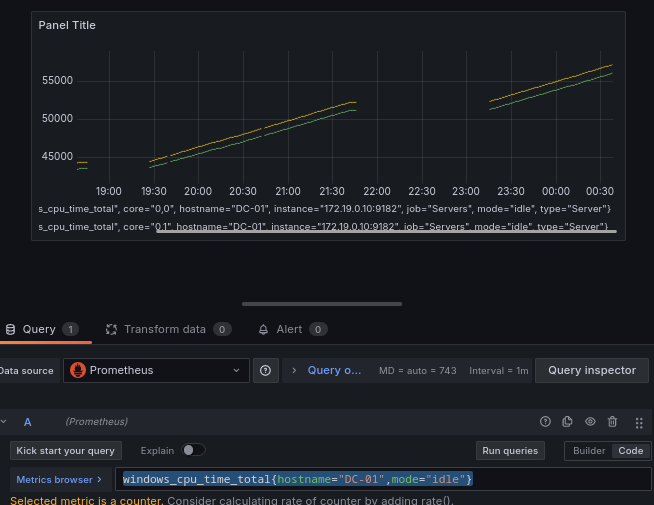
Vamos empezar a trabajar con rangos temporales, agregando la función irate, que calcula la tasa instantánea de aumento por segundo de la serie temporal en el vector de rango.
(irate(windows_cpu_time_total{hostname="DC-01",mode="idle"}[2m])) 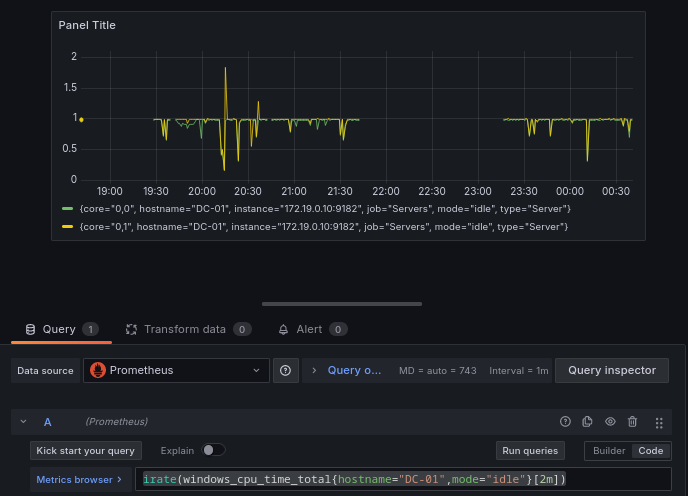
Como tenemos 2 núcleos de procesador vamos a filtrar por un único núcleo.
(irate(windows_cpu_time_total{hostname="DC-01",mode="idle",core="0,0"}[2m]))
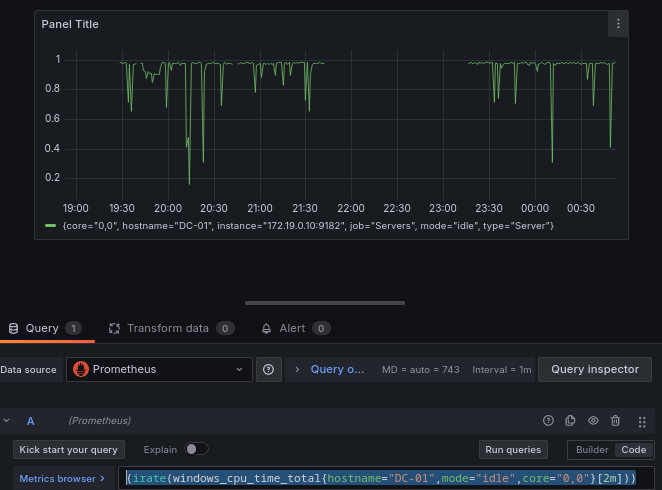
Finalmente vamos hacer una opción para convertirlo en un porcentaje, y modificar la unidad de medida del panel a un porcentaje.
100 -(irate(windows_cpu_time_total{hostname="DC-01",mode="idle",core="0,0"}[2m])) * 100
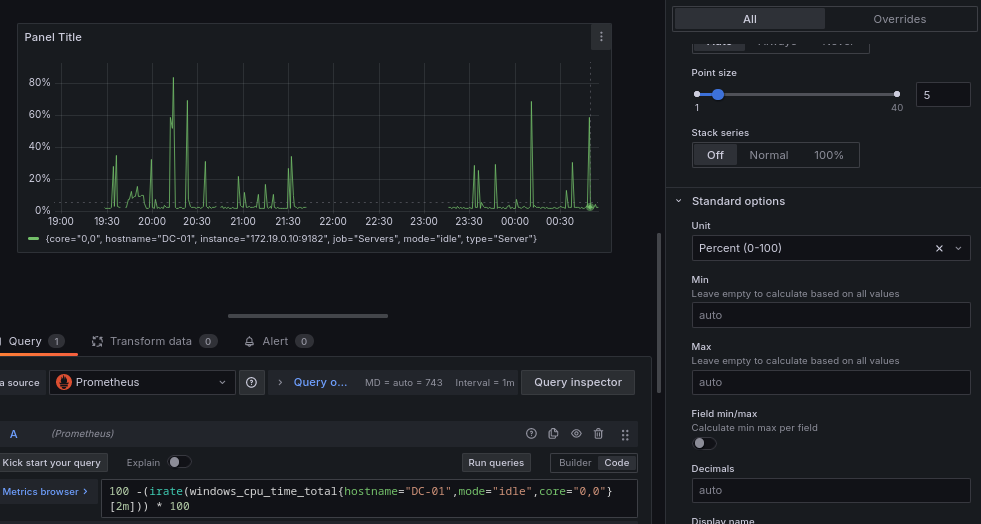
En este caso hemos calculado el uso de la CPU al restar la tasa de cambio del tiempo de inactividad de 100, la expresión intenta estimar el porcentaje de utilización de la CPU. Un mayor tiempo de inactividad indica una menor utilización de la CPU.
Creación paneles dinámicos
Hemos realizado un panel estático, ya que hemos especificado el ordenador que está monitoreando, pero esto no es útil si tenemos varios equipos y un servicio de discovery, razón por la que vamos a crear variables de entorno para tener panel dinámicos.
Para ello vamos a las opciones del dashboard.
Dentro de las opciones vamos a variables > Add variable.
Vamos a crear tres variables relacionadas entre si: la Instancia (dirección IP:puerto), el Hostname y el Job (la etiqueta job sirve como un identificador clave para diferenciar entre diferentes instancias de un servicio o aplicación).
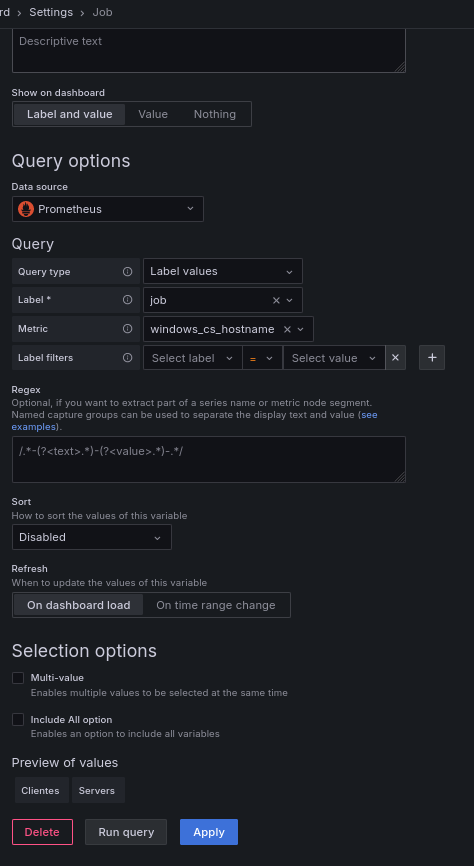
Está será la configuración de la variable Job:
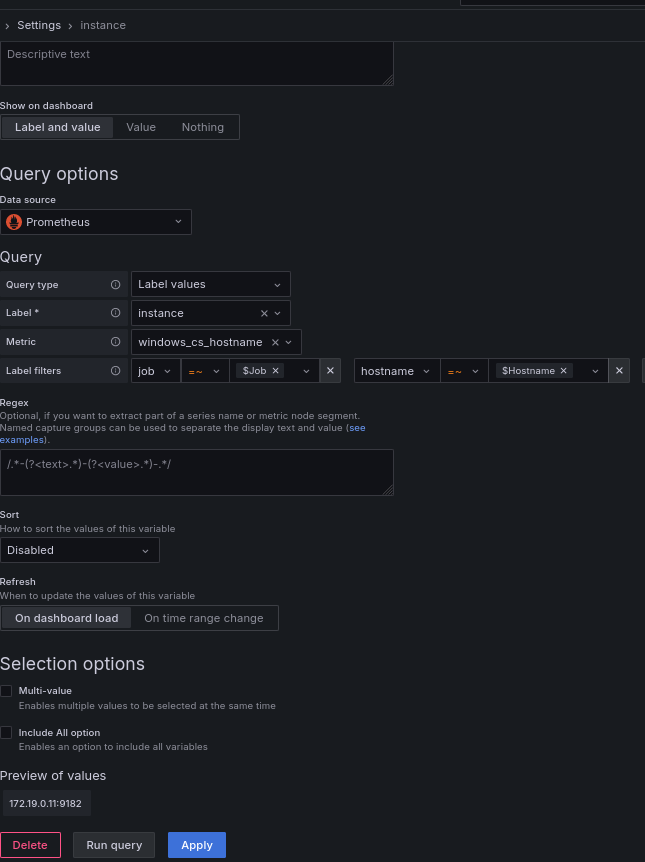
Está será la configuración de la variable Instance:
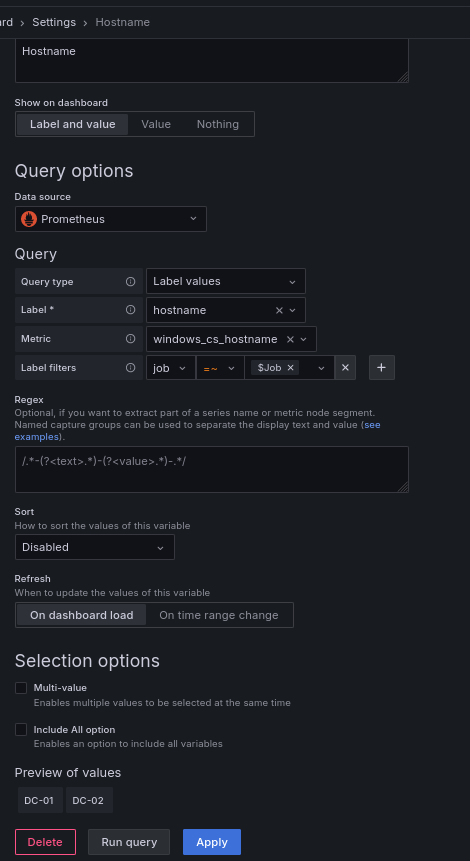
Está será la configuración de la variable Hostname:
He creado una 4º variable para hacer un panel más adelante, llamada show_hostname
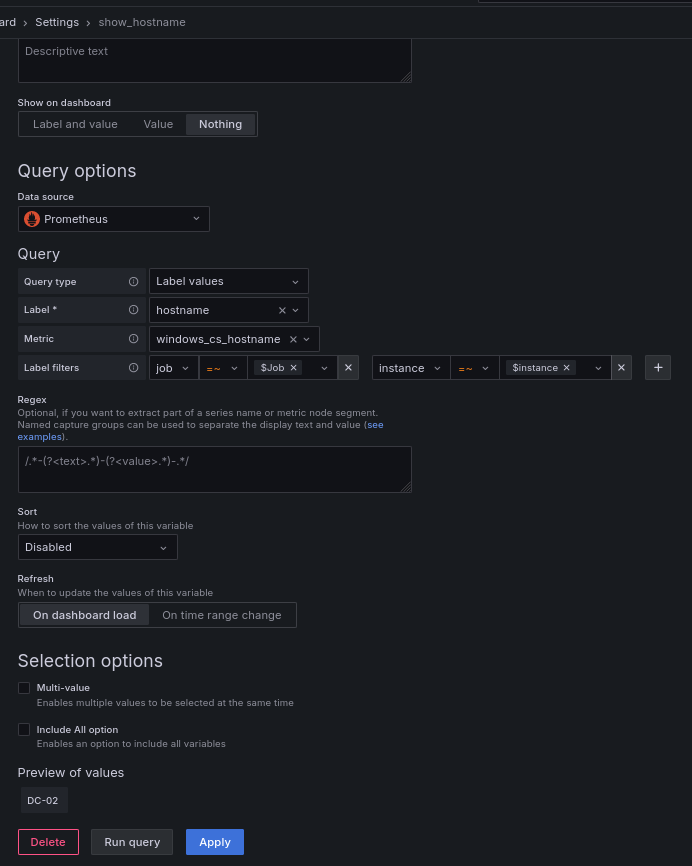
Está es la relación entre las 4 variables.
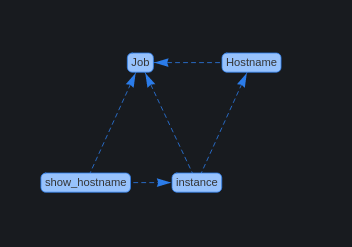
En el menú del dashboard ahora tendremos esta interfaz, donde podremos filtrar por Job de Prometheus, por Hostname o por IP.

Ahora adaptaremos el panel para hacerlo dinámico cambiando las variables estáticas por dinámicas.
100 - (avg by (instance) (irate(windows_cpu_time_total{job=~"$job",mode="idle"}[2m])) * 100)
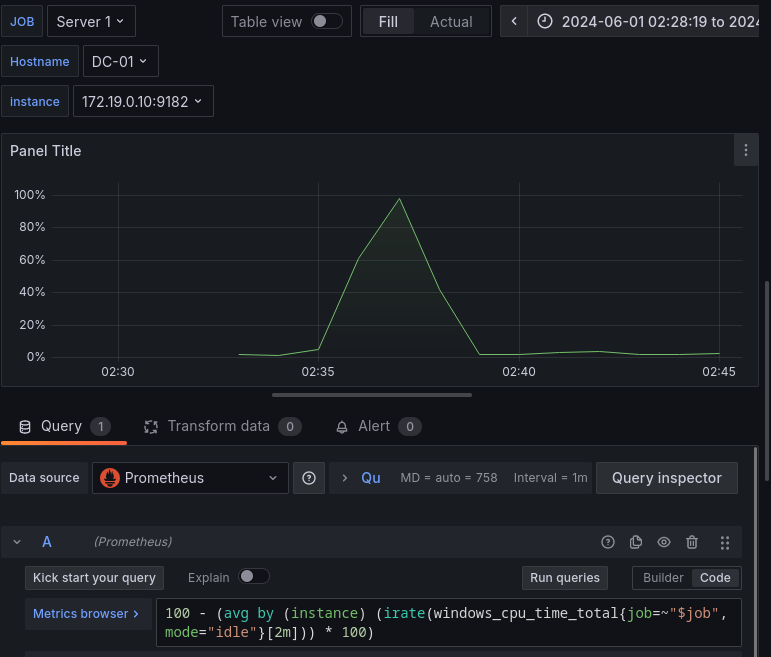
Diferencias entre las consultas:
100 -(irate(windows_cpu_time_total{hostname="DC-01",mode="idle",core="0,0"}[2m])) * 100100 - (avg by (instance) (irate(windows_cpu_time_total{job=~"$job",mode="idle"}[2m])) * 100)
En la 1º consulta es necesario especificar el Hostname y el núcleo del que queremos obtener las métricas.
En la 2º consulta ya filtramos al Hostname por la instancia y con la función avg calculamos automáticamente el uso medio de todos los núcleos del Hostname
Creación de un panel con varias métricas
Cálculo de RAM
Vamos a calcular el porcentaje de RAM usada, para ello usaremos:
windows_cs_physical_memory_bytes: Total de RAM en el sistemawindows_os_physical_memory_free_bytes: Total de RAM libre
Así obtendríamos la relación entre las memorias.
windows_os_physical_memory_free_bytes{job=~"$job"} / windows_cs_physical_memory_bytes{job=~"$job"}
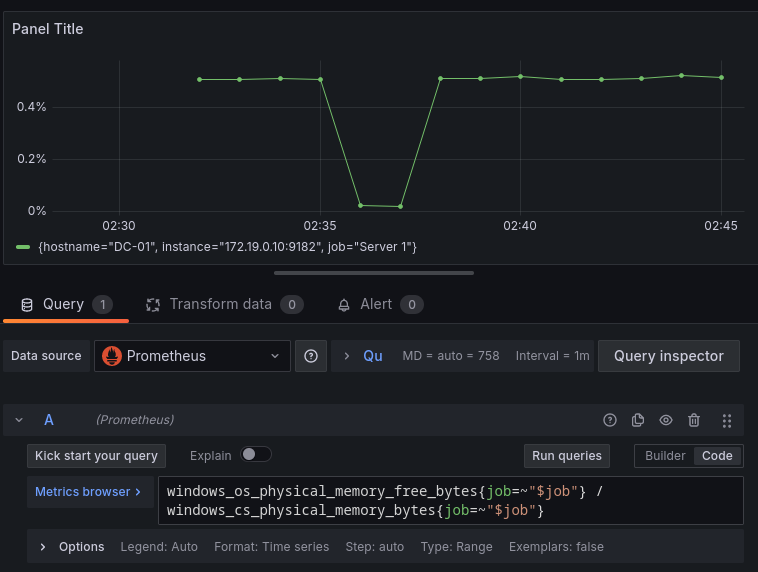
Así obtendríamos el porcentaje de uso de la memoria RAM:
100.0 - 100 * windows_os_physical_memory_free_bytes{job=~"$job"} / windows_cs_physical_memory_bytes{job=~"$job"}
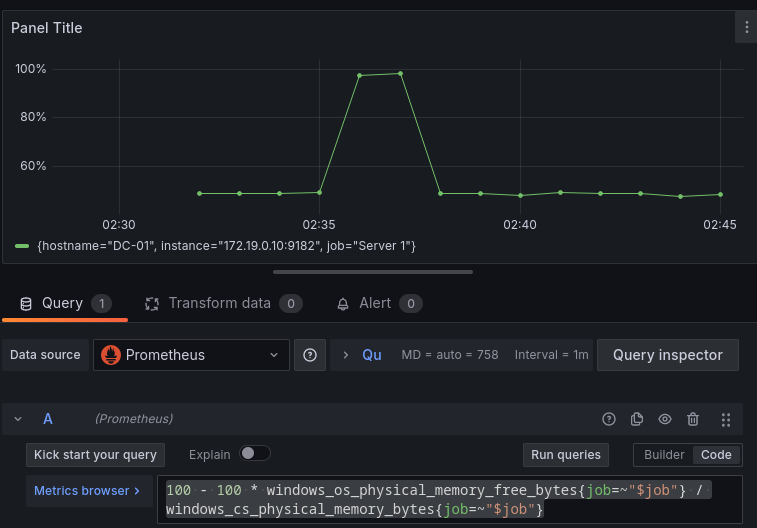
Control de red
Hasta ahora sólo estábamos usando 1 query para obtener los paneles, pero podremos utilizar varias querys para obtener panel más complejos, por ejemplo vamos a crear upanelon dos querys, una para medir los datos enviados por las interfaces de red y otra query para los datos recibidos.
Datos enviados:
max by (instance) (irate(windows_net_bytes_sent_total{job=~"$job",nic!~"(?i:(.*(isatap|VPN).*))"}[2m]))*8Datos recibidos:
-max by (instance) (irate(windows_net_bytes_received_total{job=~"$job",nic!~"(?i:(.*(isatap|VPN).*))"}[2m]))*8
En estas querys estamos usando un filtro de expresiones regulares para que no incluya las tarjetas de red con el patrón isatap o VPN, para evitar interfaces tunelizadas.
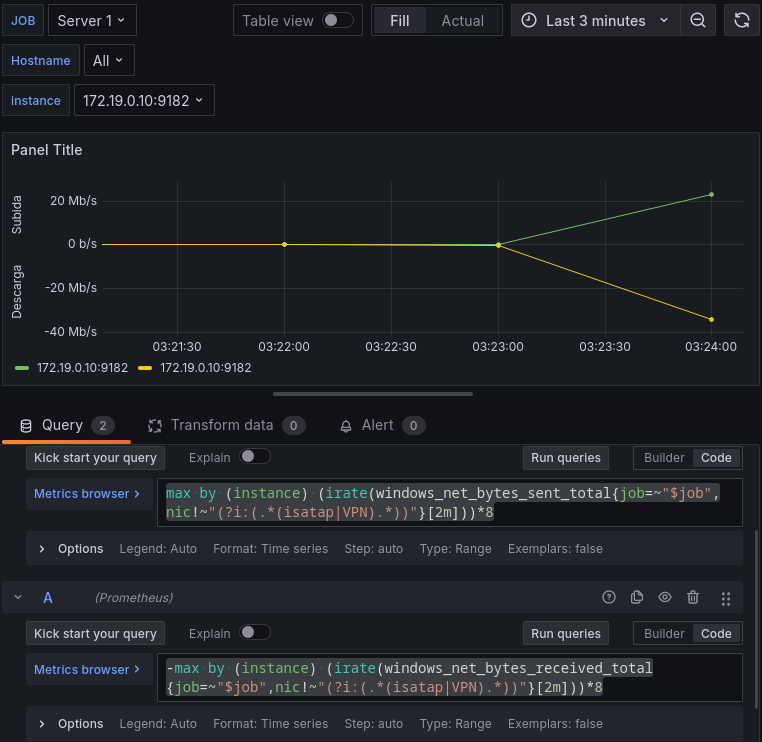
Control de servicios
También hay funciones que nos permites hacer lo contrario que el ejemplo anterior, con una única query podemos obtener varios datos, por ejemplo:
sum(windows_service_state{job=~"$job",instance=~"$instance"}) by (state)
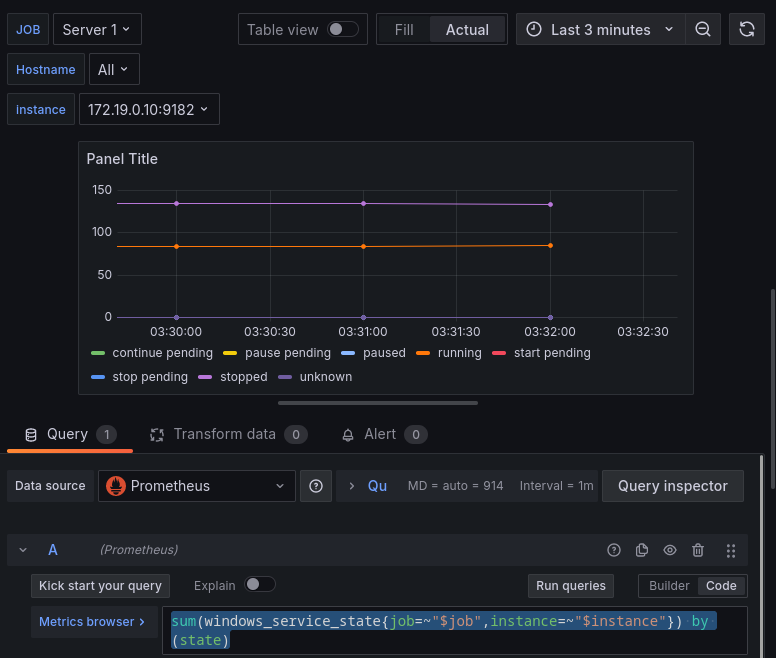
Esto es posible porque la query agrupa los servicios por el estado.
Para hacerlo más visual, ya que el objetivo es conocer el estado de un sistema simplemente mirando los paneles vamos a agruparlos a la derecha del panel en modo tabla, para ello:
- Habilitamos la leyenda, especificamos que se muestre a la derecha y le indicamos que valores deberá mostrar en la leyenda,
Last *muestra los últimos valores excluyendo los nulos.
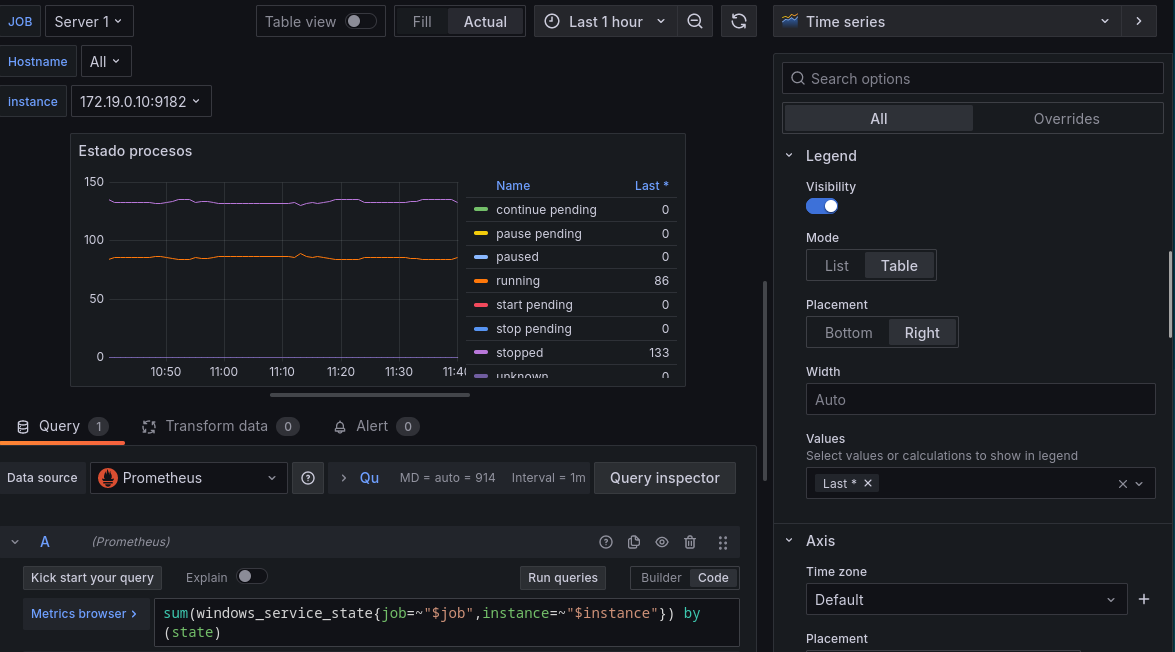
Control de discos
Podemos monitorizar por ejemplo el espacio ocupado en las distintas particiones de los equipos, o su velocidad de escritura y lectura, así como el I/O de una unidad, empezaremos con el espacio ocupado por las unidades.
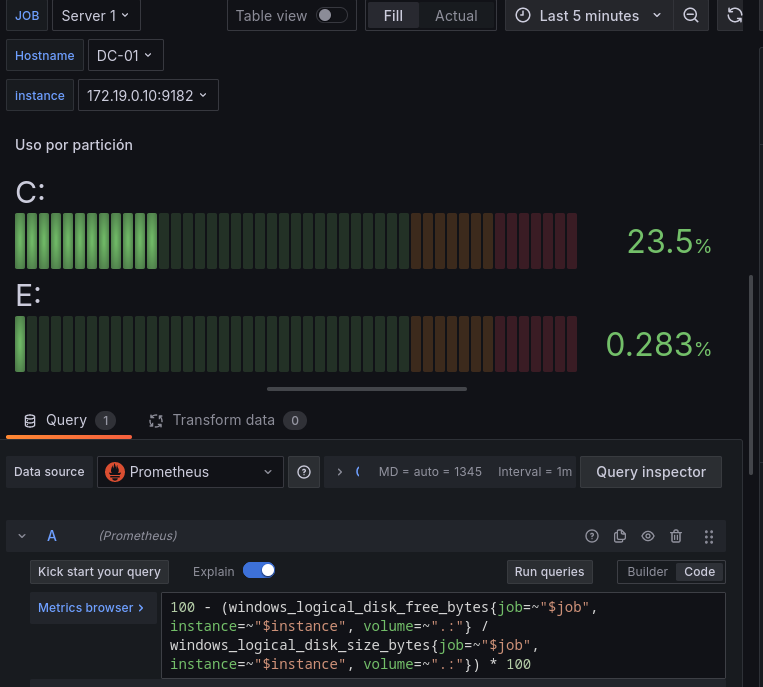
- Para el espacio ocupado por las particiones usaremos una query con dos consultas:
windows_logical_disk_free_bytes: Espacio sin usar en el disco.windows_logical_disk_size_bytes: Tamaño total del disco.
100 - (windows_logical_disk_free_bytes{job=~"$job", instance=~"$instance", volume=~".:"} / windows_logical_disk_size_bytes{job=~"$job", instance=~"$instance", volume=~".:"}) * 100
Esa query filtra por Job e Instance y busca volúmenes con el formato X: que es el formato estándar en sistemas Windows, y calcula el porcentaje como hemos hecho en ejemplos anteriores.
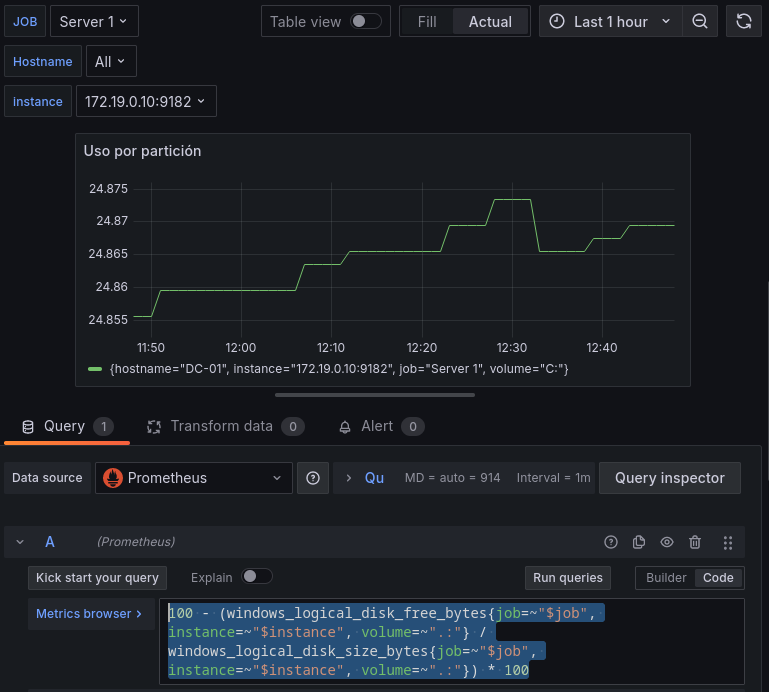
Hasta ahora hemos usado panel de series temporales, pero hay más formatos, por ejemplo para este caso podríamos ponerlo como medidor o Gauge, lo cual sería más acorde.
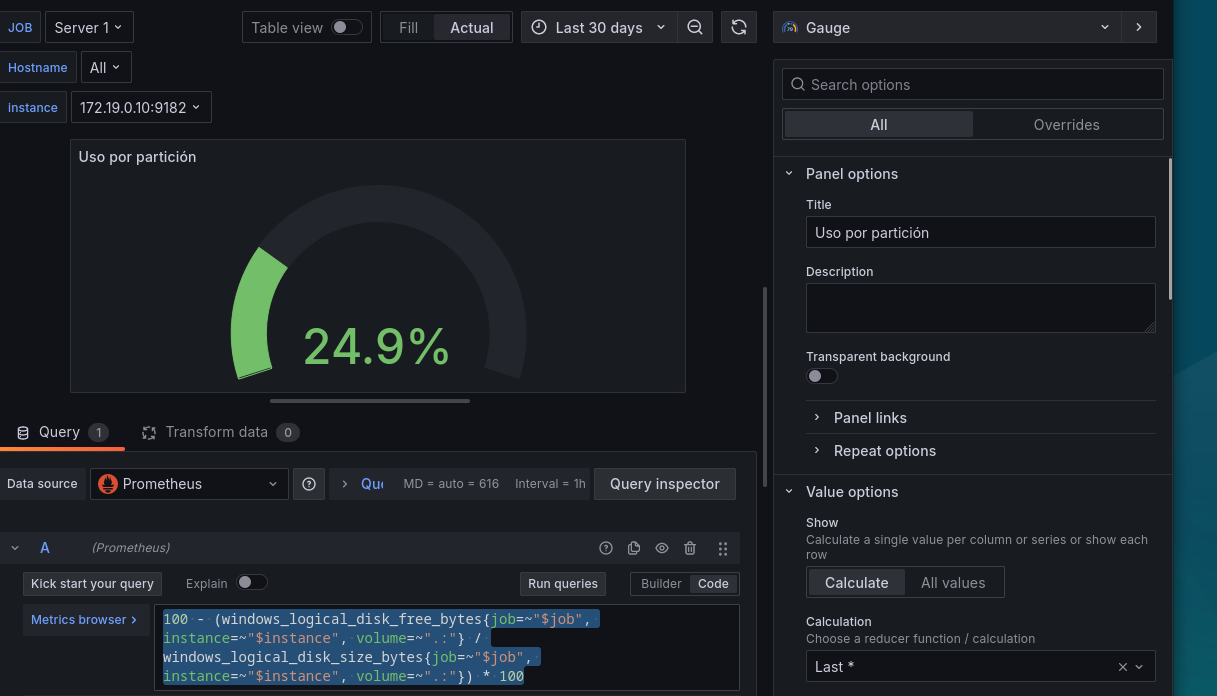 ]
]
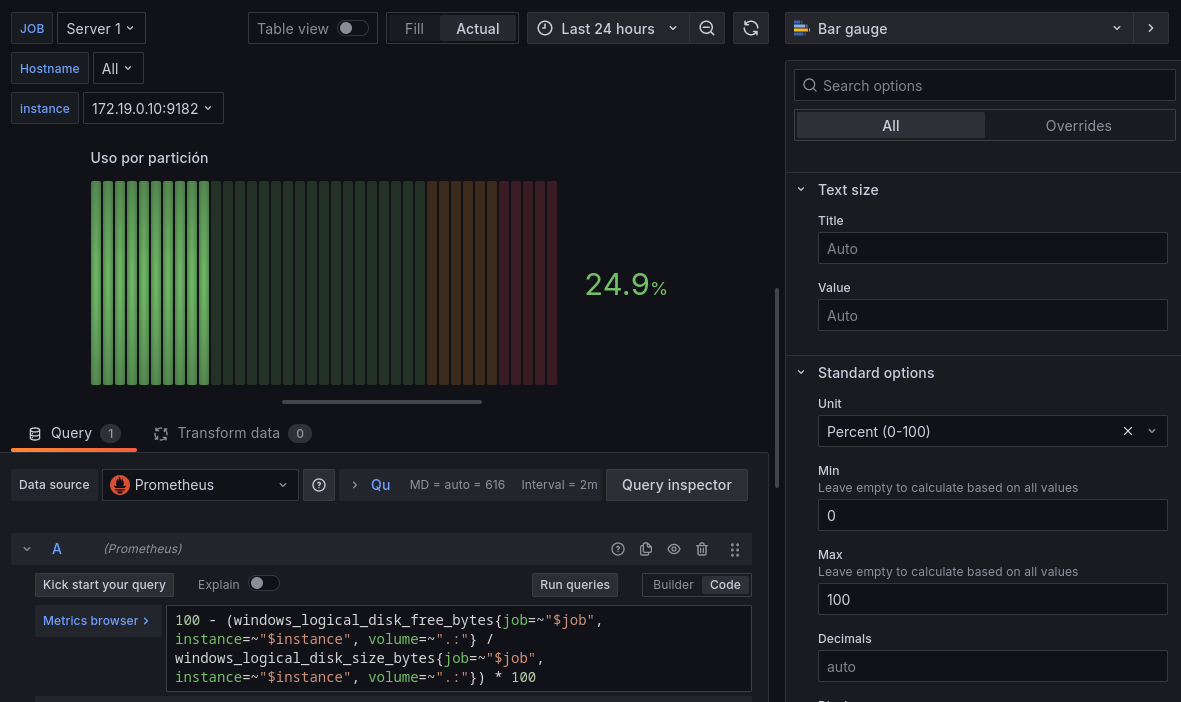
También podríamos usar un Bar Gauge o diagrama de barras.
Si añadimos un nuevo disco en el servidor al haber 2 expresiones regulares que cumplen la expresión el panel se convertirá en algo similar a esto, con el nombre completo.
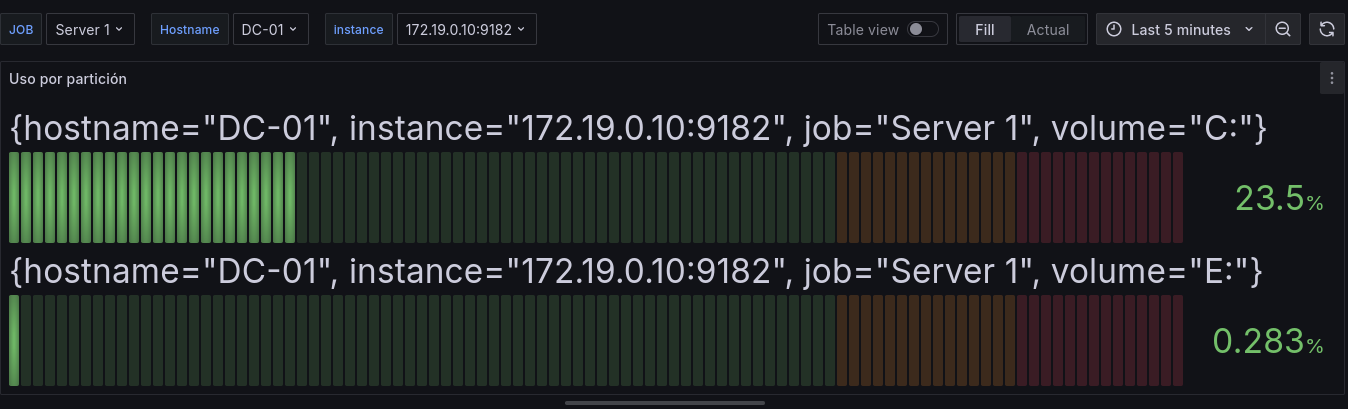
Para solucionarlo vamos a Query inspector > JSON > buscamos la etiqueta de "legendFormat", que debería estar en "__auto" > la cambiamos por ""
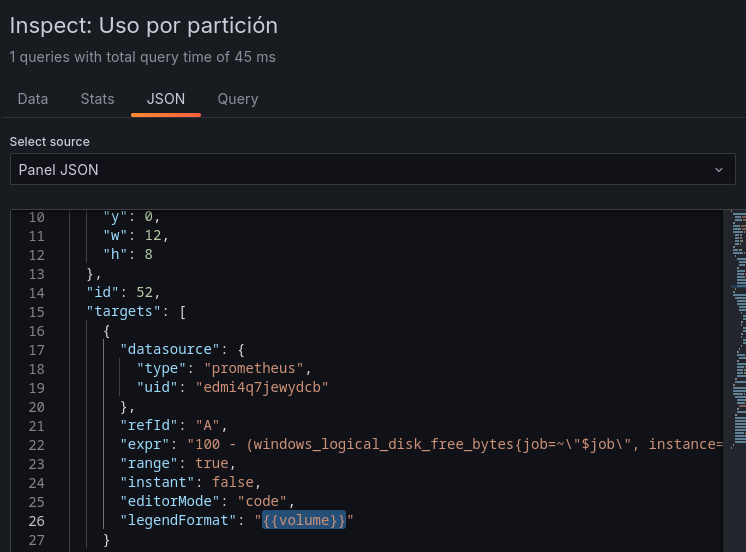
Tras aplicarlo nos aparecerá correctamente el nombre del volumen.
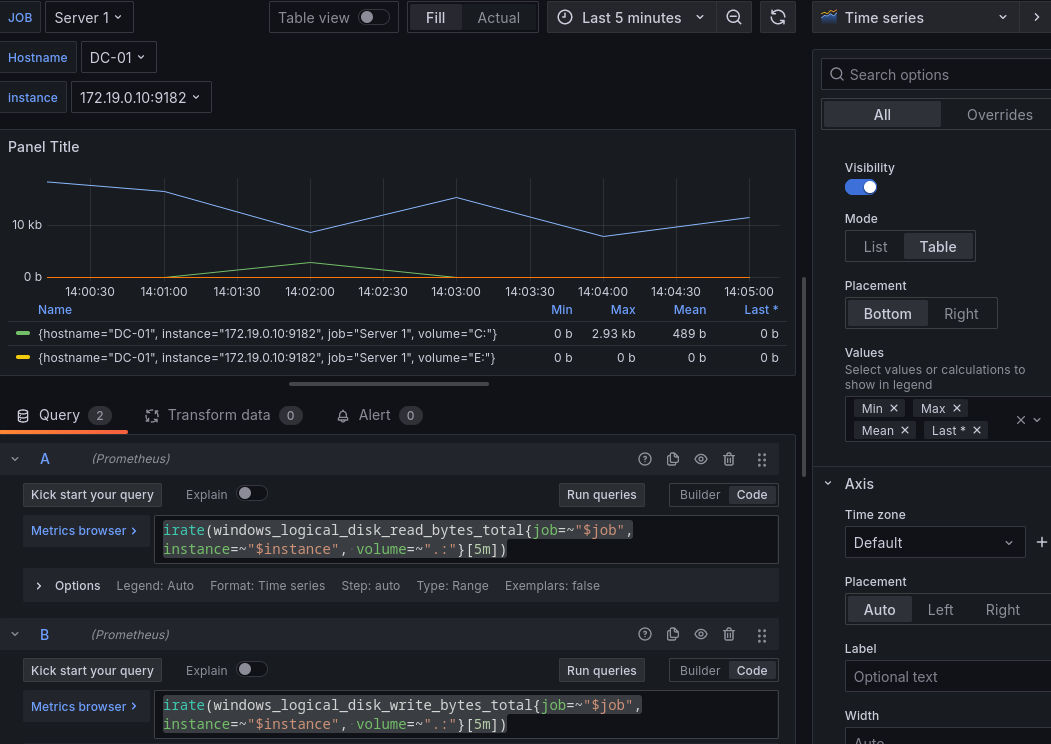
- Para la velocidad de escritura y lectura:
Crearemos 2 querys distintas, una para la velocidad de lectura y otra para la velocidad de escritura, empezaremos por la de lectura:
irate(windows_logical_disk_read_bytes_total{job=~"$job",instance=~"$instance", volume=~".:"}[5m])
Y la de escritura:
irate(windows_logical_disk_write_bytes_total{job=~"$job",instance=~"$instance", volume=~".:"}[5m])
Filtraremos en las opciones del panel para que nos muestre la velocidad mínima, máxima, la media y la última.
Como nos encontramos el mismo error con el nombre repetiremos los pasos de la opción anterior, en este caso añadiendo también una etiqueta descriptiva en el nombre para diferenciarlos.
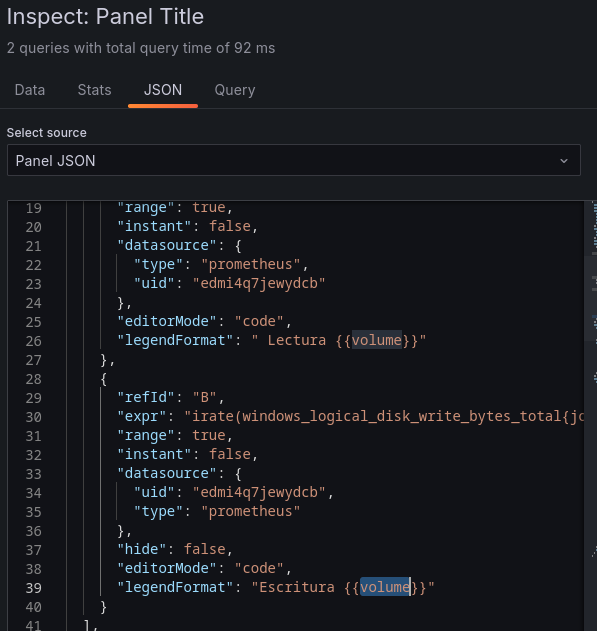
Quedando el panel tal que así:
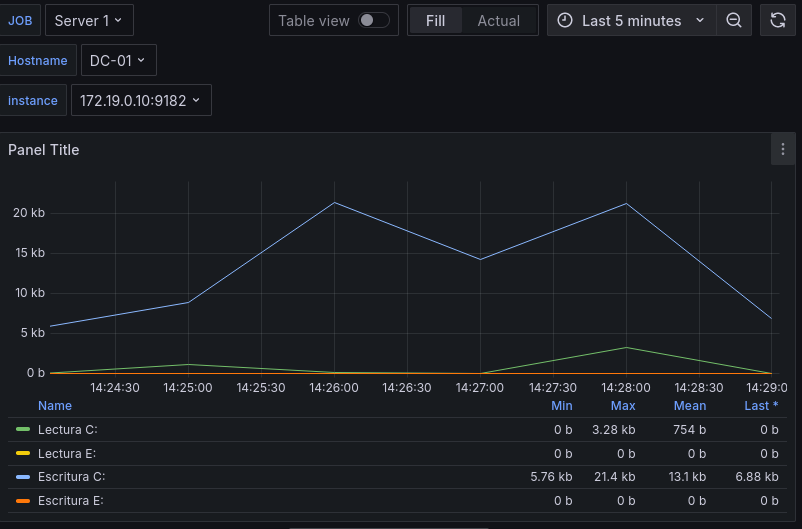
Otro dato interesante que monitorear de los discos es el número de operaciones de lectura y escritura por segundo, conocido por el termino Disk I/O, para ello utilizaremos dos querys.
max by (instance) (irate(windows_logical_disk_writes_total{job=~"$job", volume=~".:"}[2m]))
-max by (instance) (irate(windows_logical_disk_reads_total{job=~"$job", volume=~".:"}[2m]))
En la 1º query obtenemos el total de escrituras de disco por instance y en la segunda obtenemos el total por instance, la segundo está en negativo para mejorar la visibilidad.
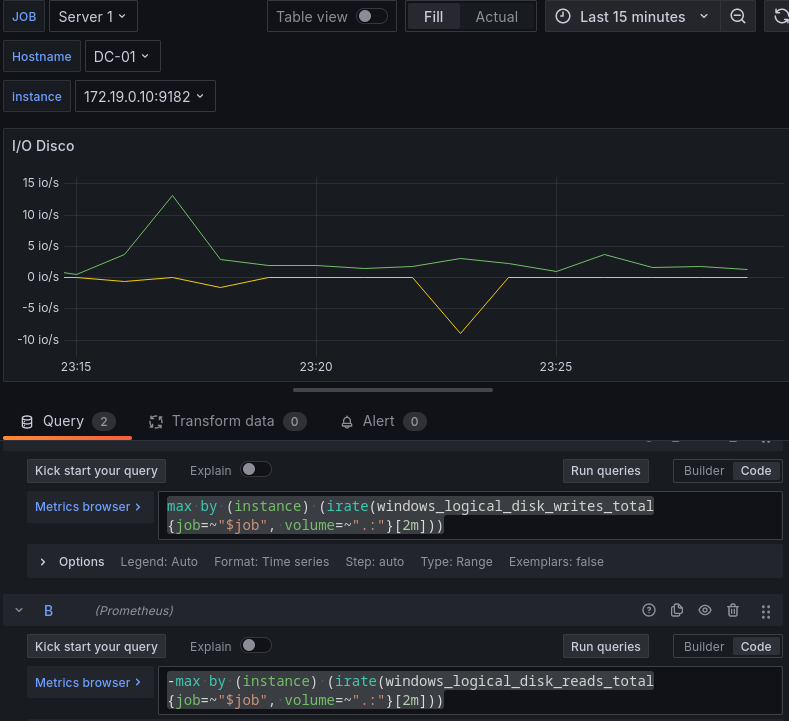
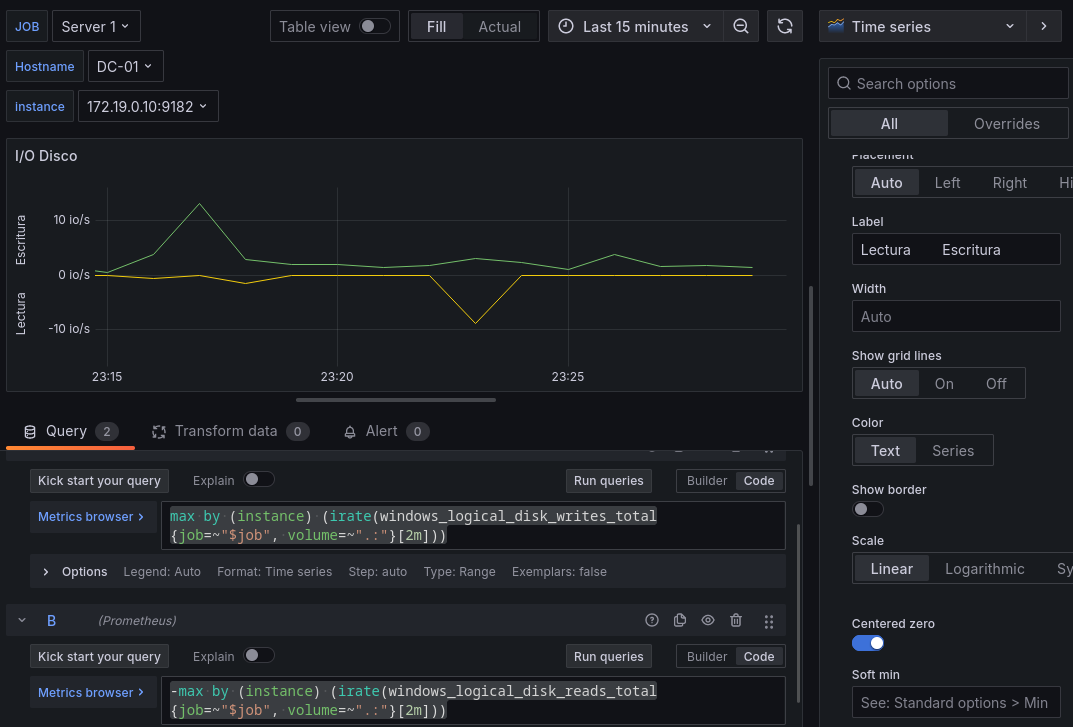
Para mejorar su visibilidad modificaremos algunas de las opciones por defecto, añadiremos unas etiquetas para identificar fácilmente los datos que estamos viendo, y centraremos la serie temporal en el 0, con la opción de centered zero.
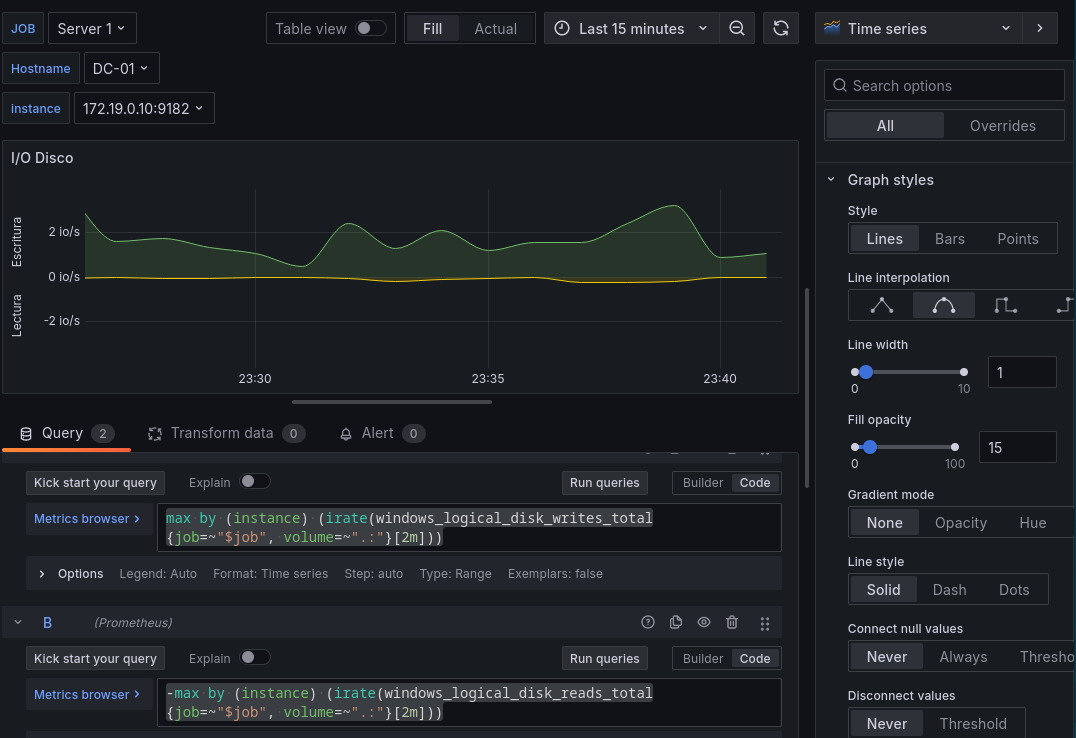
Para mejorar un poco más la visualización vamos a introducir colores diferenciales entre las dos querys, para ello en la parte de Graph styles buscaremos la opción de Fill opacity y pondremos un valor bajo para que no moleste, en mi caso elegiré el 15.
Filas
Ahora mismo tenemos todos los paneles mezclados y sin ningún orden, para esto existen las filas o Rows en Grafana, las filas nos permiten aplicar filtros, y agrupar paneles en función de su propósito o finalidad, para ello iremos a Add > Row y creara un Row o Fila.
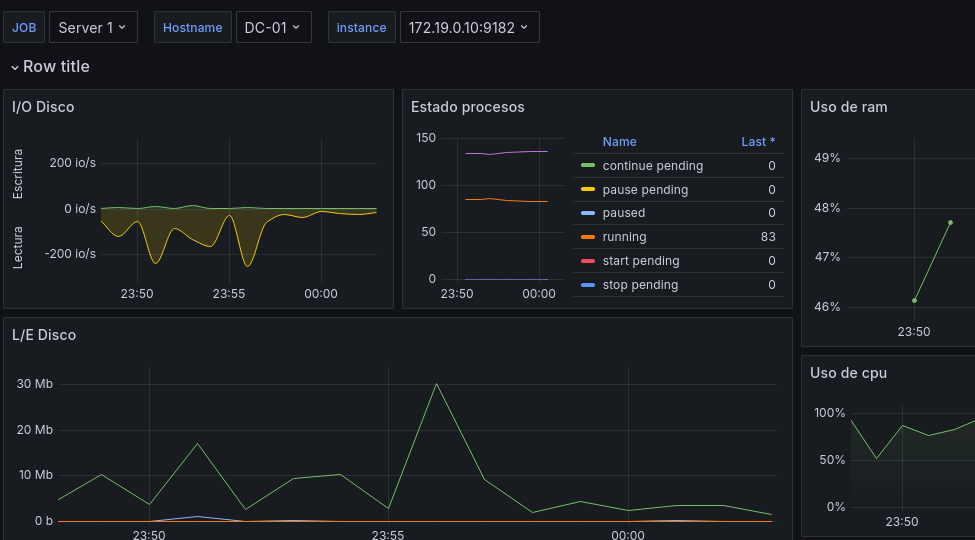
Empezaremos personalizando el Row pulsando sobre la rueda que aparece al pasar el ratón por encima:

Empezamos modificando su nombre, añadiendo la variable [$job], para que nos muestre el nombre del job que tengamos seleccionado, por ejemplo con el job server 1 seleccionado.

Y con el job server 2 seleccionado:

Ahora añadiremos un panel como tabla que nos muestre información relevante, como el hostname, el dominio, la dirección IP, el SO, el Uptime, la RAM, los porcentajes de CPU, RAM usados y almacenamiento usados, así como el número de procesos o de servicios activos.
Para ello añadiremos un nuevo panel y seleccionaremos el formato de tabla.
Para este apartado necesitaremos las transformaciones, las transformaciones son herramientas que permiten modificar, reorganizar y combinar los datos provenientes de las consultas antes de que se muestren en los paneles.
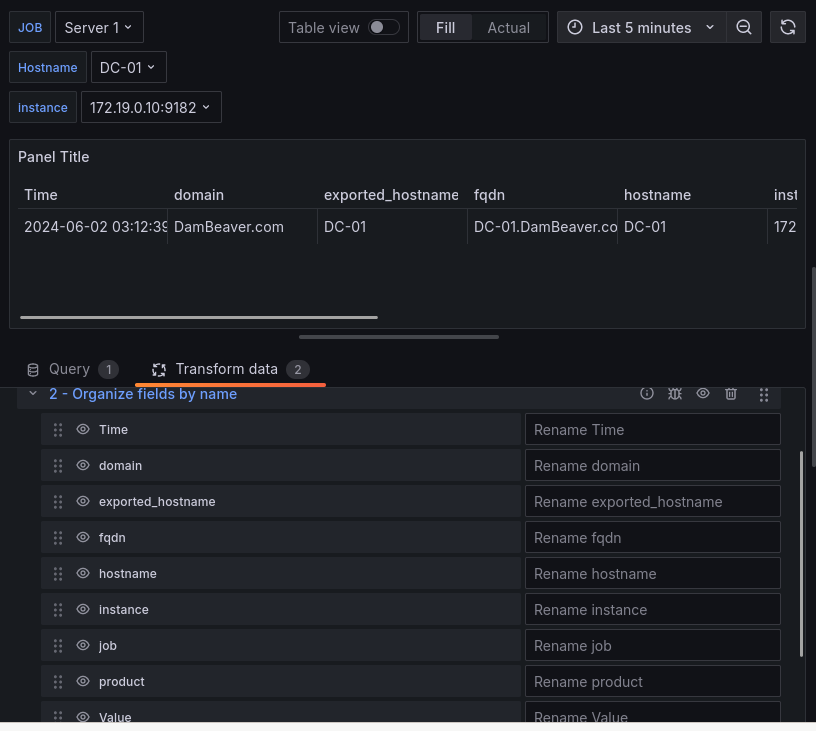
Por ejemplo la siguiente query con la instancia o el hostname de DC-01 seleccionado:
windows_cs_hostname nos devolvería 1 como valor y como nombre {__name__="windows_cs_hostname", domain="DamBeaver.com", exported_hostname="DC-01", fqdn="DC-01.DamBeaver.com", hostname="DC-01", instance="172.19.0.10:9182", job="Server 1"}
Con las transformaciones podríamos hacer un filtrado para extraer el dominio o el hostname para crear el panel, en este panel usaremos las siguientes transformaciones:
Merge series/tables Esta transformación es útil para combinar los resultados de varias consultas en un solo resultado, lo cual es particularmente útil cuando se utiliza la visualización del panel de tabla.
Organize fields by name Esta transformación es útil para brindar la flexibilidad de cambiar el nombre, reordenar u ocultar los campos devueltos por una sola consulta en su panel.
Tras aplicar estas transformaciones podremos empezar con las querys, empezaremos con la query:
windows_os_info{job=~"$job"} * on(instance) group_right(product) windows_cs_hostname
windows_os_info{job=~"$job"} * on(instance) esta parte agrupa todas las métricas de la etiqueta windows_os_info
group_right(product) esta parte recupera el valor a la derecha de la etiqueta producto.
windows_cs_hostname recupera el hostname.
Con todo eso obtendremos el siguiente panel:
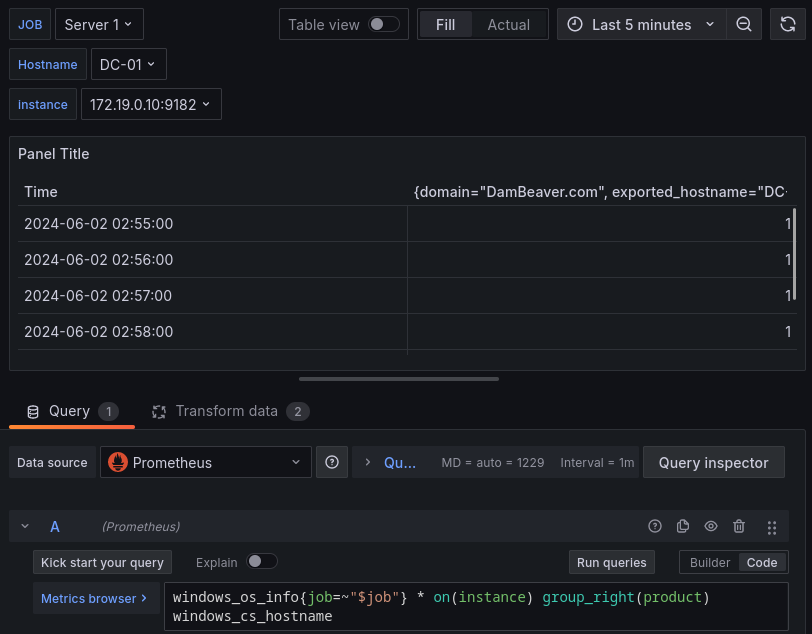
Para separar los valores usaremos los overrides
El override, también conocido como anulación de campos, es una funcionalidad que permite modificar o personalizar la configuración de paneles, campos y otras propiedades dentro de un dashboard.
Para ello añadimos un nuevo campo con Add field override > Field with name
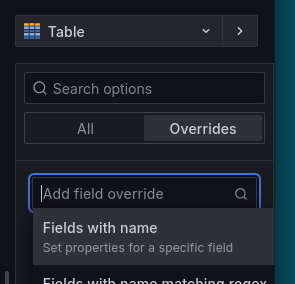
En la query desplegaremos las opciones y seleccionaremos las opciones:
Legend>VerboseFormat>TableType>Instant
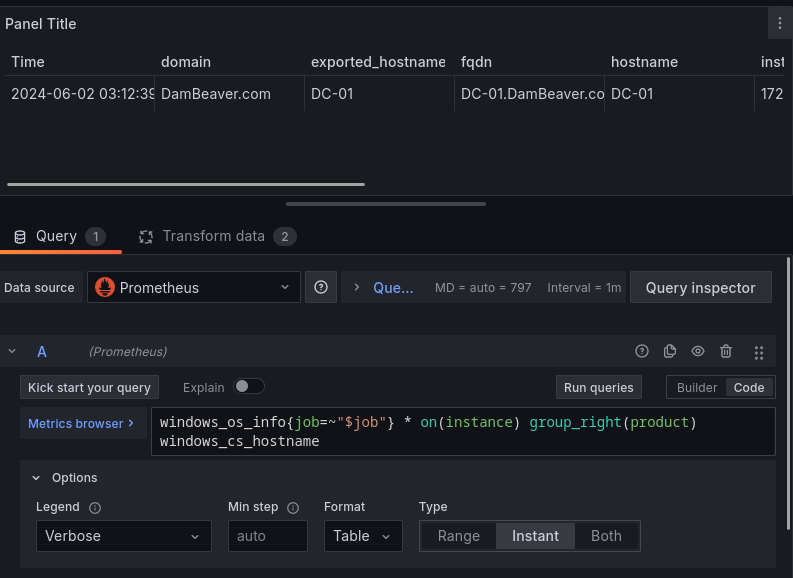
En el campo override ahora podemos sobreescribir cada valor por defecto, por ejemplo en el producto, sobreescribiremos que el campo tenga un ancho de 300 con la siguiente configuración.
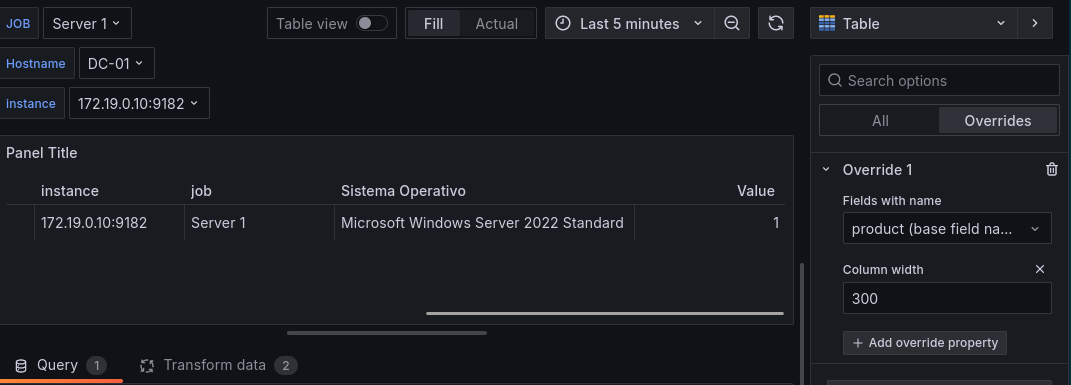
Ahora que hemos configurado correctamente los parámetros necesarios podremos ver que en las transformaciones una lista de campos para elegir cuales veremos y cuales no, así como la posibilidad de renombrarlos.
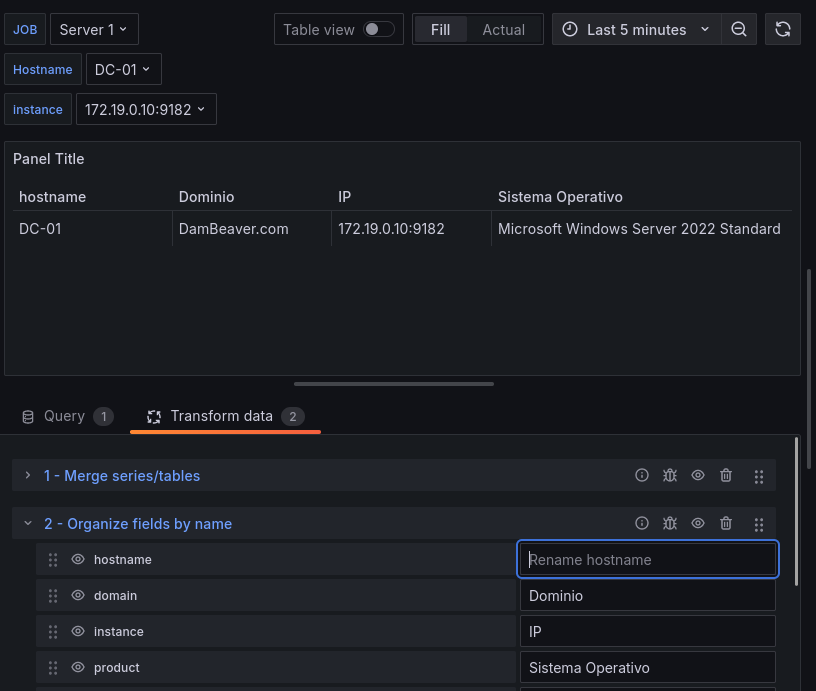
Haremos un filtrado para sólo mostrar el Hostname, el dominio, la IP, y el SO, también podemos cambiar el orden de los valores.
Ahora añadiremos más campos como el Uptime, la RAM, los porcentajes de CPU, RAM usados y almacenamiento usados, así como el número de procesos o de servicios activos.
Uptime: Usaremos la query
time() - windows_system_system_up_time{job=~"$job"}y obtendremos el uptime en segundos, para adaptarlo usaremos el override apuntando al campo del uptime, y le indicaremos que el campo esta en segundos, Grafana automáticamente lo pasará a la unidad que corresponda según la cantidad.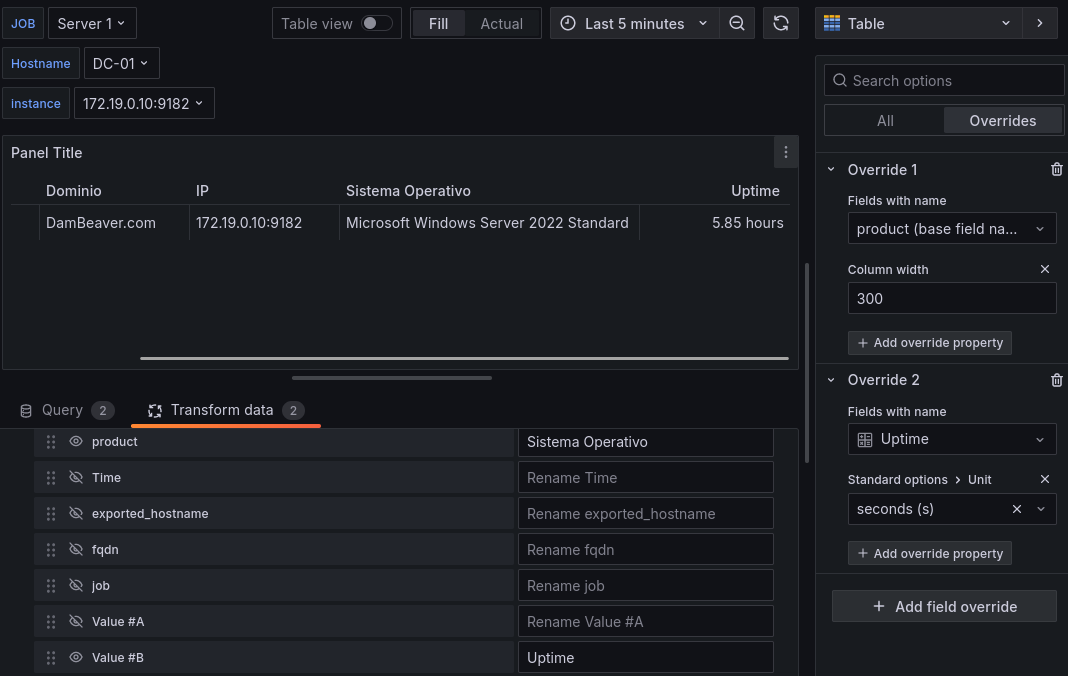
Total RAM: Usaremos la ya conocida query
windows_cs_physical_memory_bytes{job=~"$job"} - 0Usaremos el override para convertirlo a Gibibytes.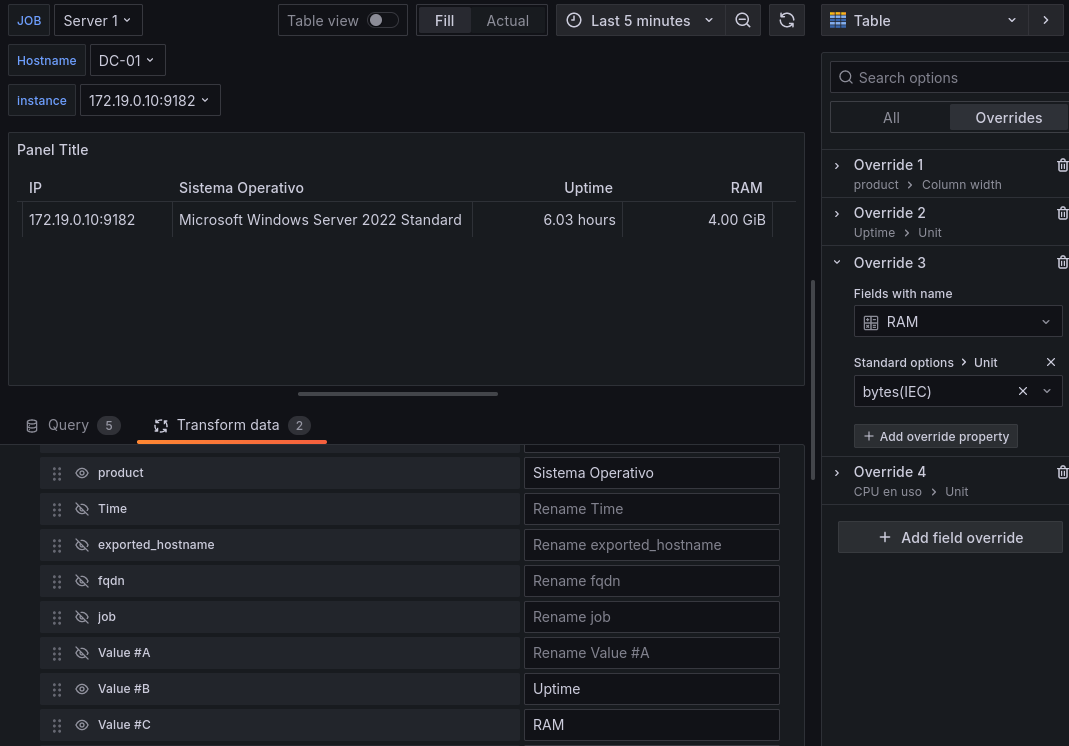
CPU en uso Usaremos la ya conocida query
100 - (avg by (instance) (irate(windows_cpu_time_total{job=~"$job",mode="idle"}[2m])) * 100)Usaremos igualmente el override para convertirlo a porcentaje.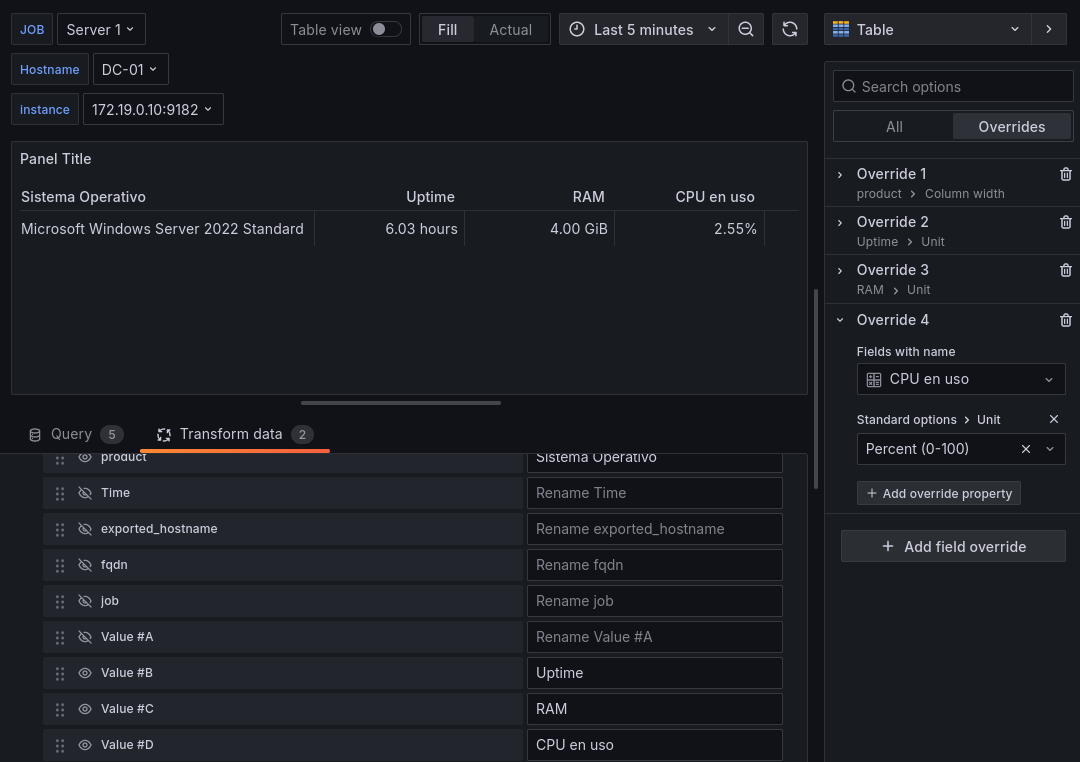
RAM en uso Usaremos la ya conocida query
100 - 100 * windows_os_physical_memory_free_bytes{job=~"$job"} / windows_cs_physical_memory_bytes{job=~"$job"}Usaremos igualmente el override para convertirlo a porcentaje.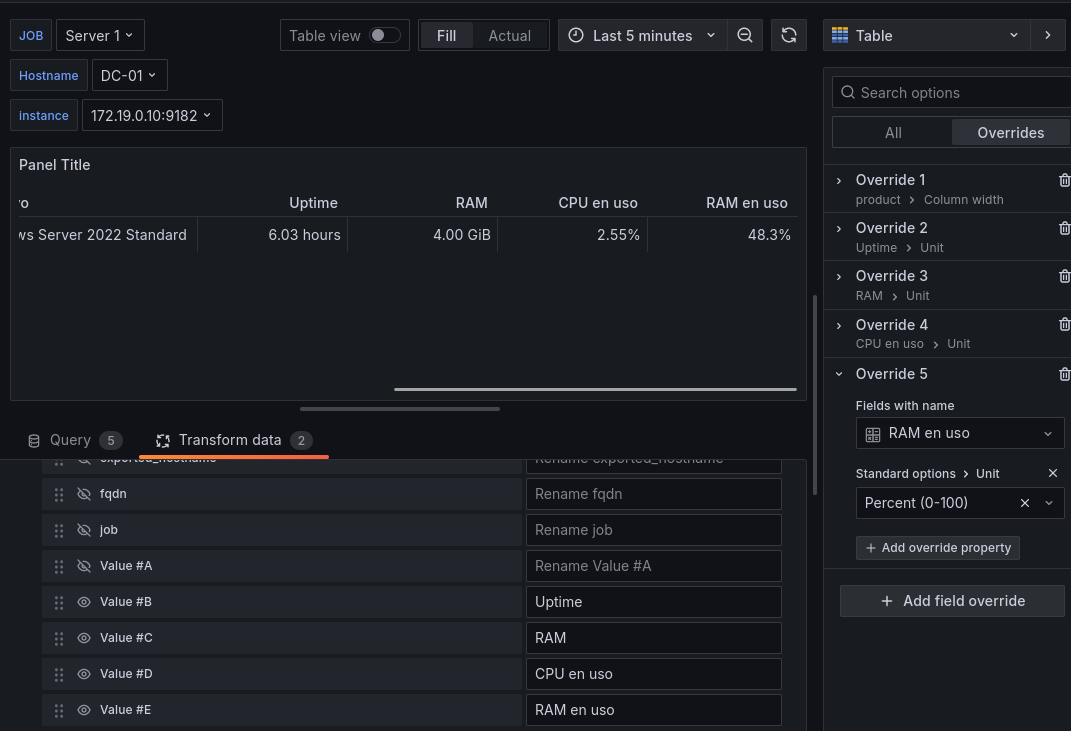
Almacenamiento C en uso Usaremos la ya conocida query
100 - (windows_logical_disk_free_bytes{job=~"$job",volume=~"C:"}/windows_logical_disk_size_bytes{job=~"$job",volume=~"C:"}) * 100Usaremos igualmente el override para convertirlo a porcentaje.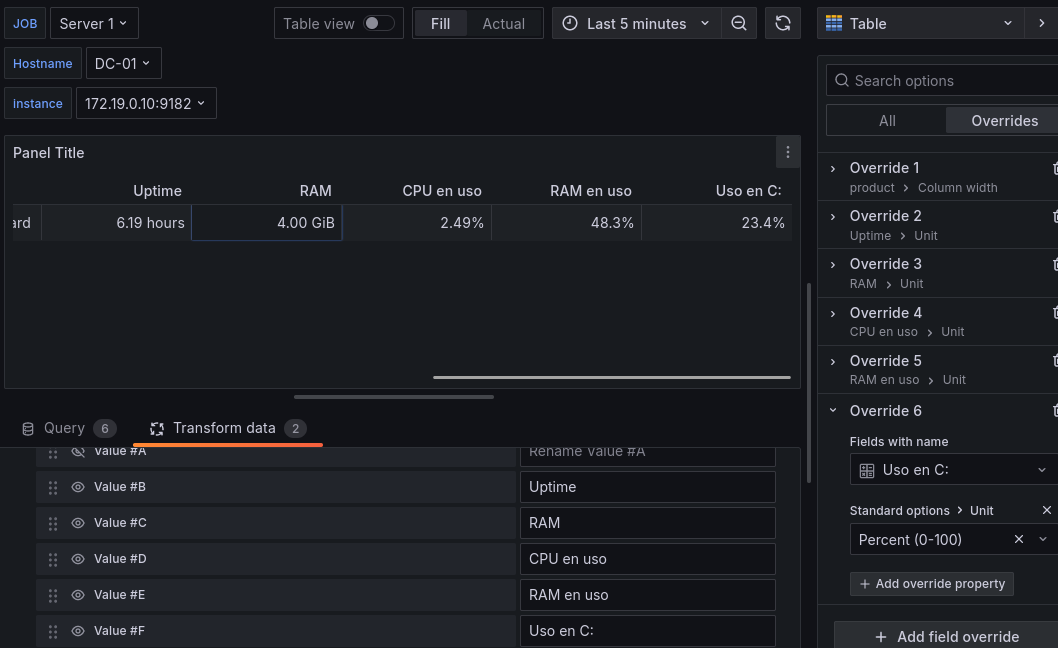
Número procesos Usaremos la query
windows_os_processes{job=~"$job"}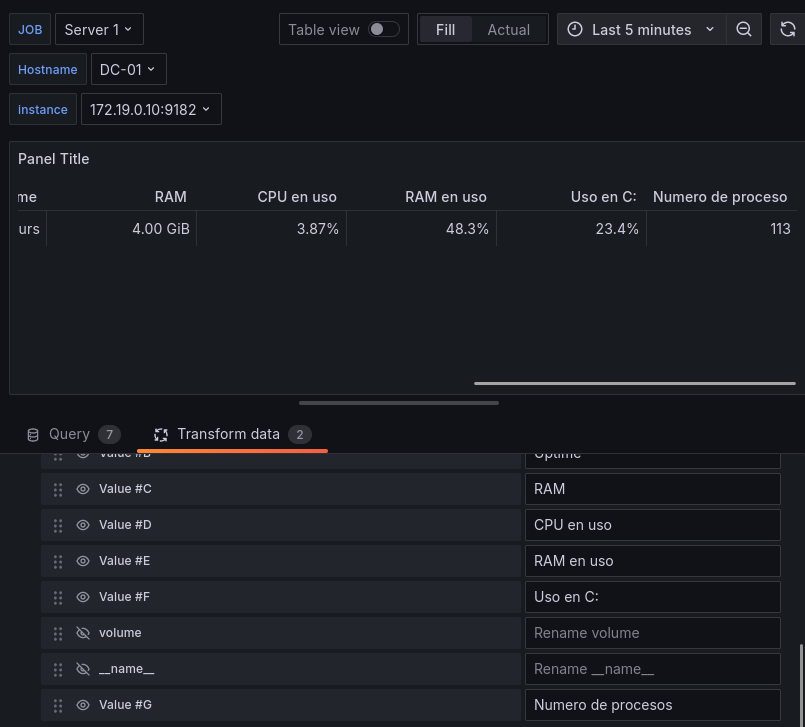
Número servicios activos Usaremos la query
sum by (instance) (windows_service_state{job=~"$job",state=~"running"})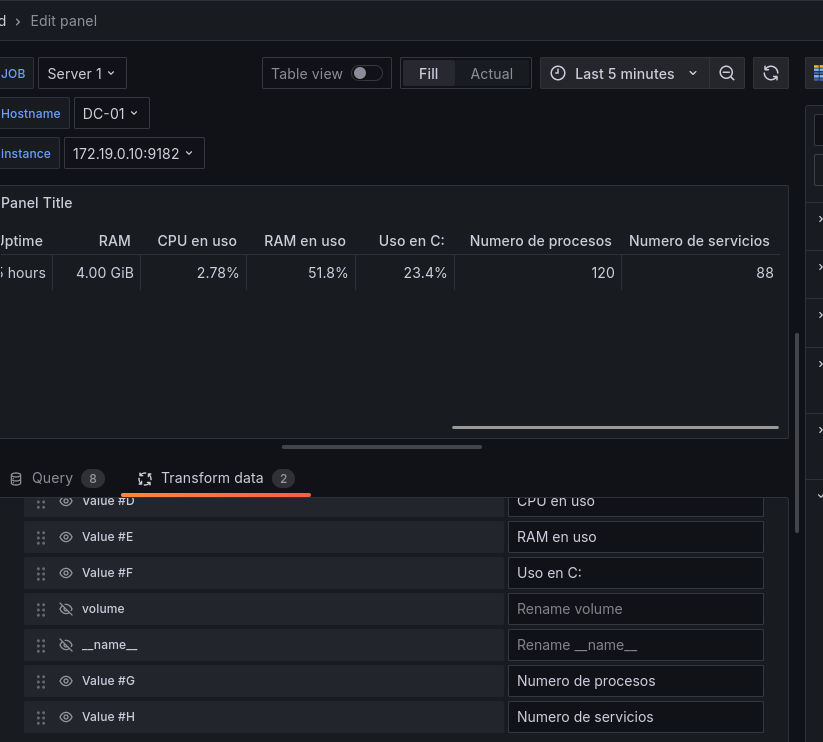
Detalles finales: Con el override podemos añadir diferentes colores, añadiremos colores en campos como la CPU o la RAM para hacerlo más visual.
Para ello en las opciones de
overridepulsamos enAdd override property > Cell options > Cell type > Colored Background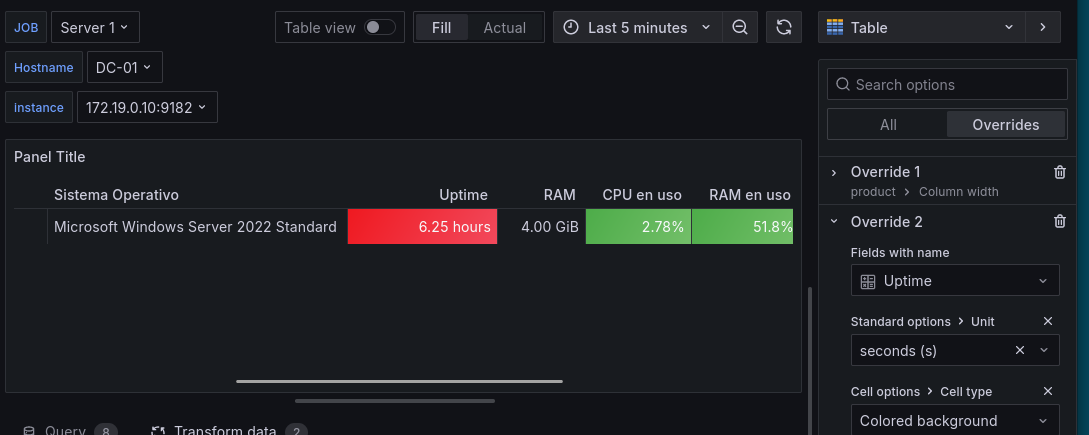
También podemos poner alertas visuales en caso de que algún campo suba en exceso, para ello en las opciones de
overridepulsamos enAdd override property > Threshold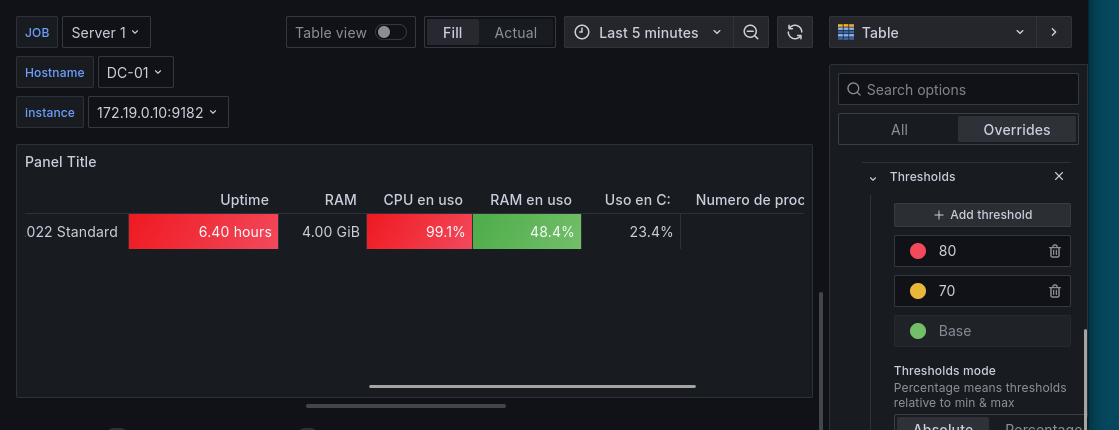
Quedaría este panel visual tal que así:

Organización
Ahora que conocemos las filas o rows, vamos a organizar el panel por secciones, una dedicada a cada apartado importante, tendremos el panel principal creado en el apartado anterior, una sección para ver los datos más relevantes de la instancia actual, otra sección para datos menos relevantes y finalmente una sección para monitorear el estado de los servicios más importantes.
Panel principal
Ya lo hemos hecho en el apartado anterior
Datos relevantes
Utilizaremos paneles hechos anteriormente y crearemos algunos nuevos, empezaremos cambiando el formato de la RAM para hacerlo más visual y modificando la CPU con la opción de fill opacity para que sea más clara su visión.
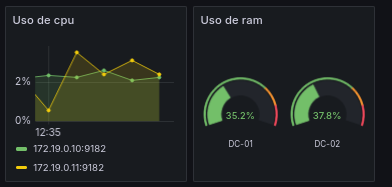
Controlaremos en esta sección también el tráfico de red, el I/O de los discos y la lectura/escritura de los discos.
Todo esto ya lo hemos calculado anteriormente pero cambiaremos su formatos para hacerlos más visuales, modificaremos el Tráfico de red con la opción de fill opacity para que sea más clara su visión, la añadiremos también al I/O del disco y modificaremos la Lectura/Escritura del disco para que se muestre en paneles, dando el siguiente resultado.

Y quedando está sección tal que así.
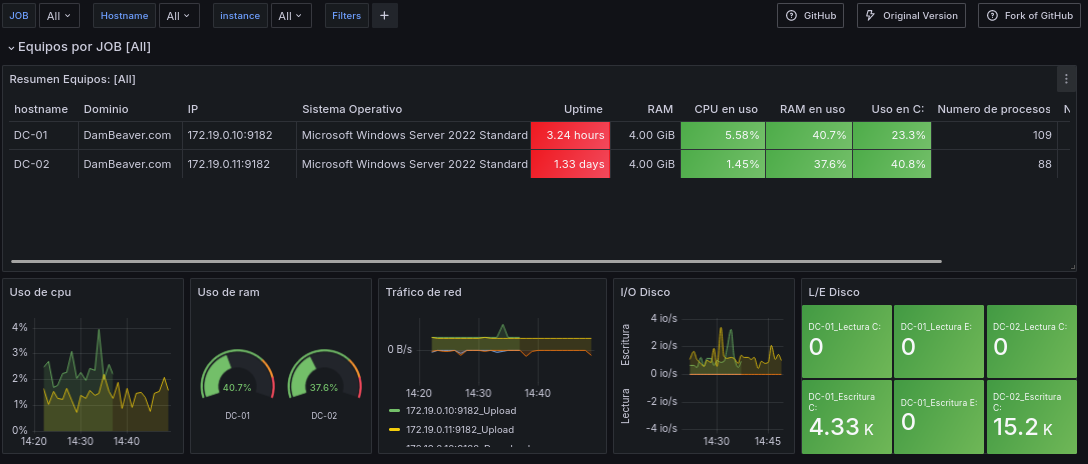
Datos Instancia
Para ver datos más específicos usaremos algunas de las antiguas querys y otras nuevas, reutilizaremos los paneles de Uso de red, Estado de servicios y Uso de partición, para ello modificaremos las querys para que obtengan los datos de cada instance:
- Uso de red: Nueva query:
max by (instance) (irate(windows_net_bytes_sent_total{instance=~"$instance",nic!~"(?i:(.*(isatap|VPN).*))"}[2m]))* 8-max by (instance) (irate(windows_net_bytes_received_total{instance=~"$instance",nic!~"(?i:(.*(isatap|VPN).*))"}[2m]))*8
- Estado de servicios: Nueva query:
sum(windows_service_state{instance=~"$instance"}) by (state)
- Uso de partición: Nueva query:
100 - (windows_logical_disk_free_bytes{instance=~"$instance", volume=~".:"} / windows_logical_disk_size_bytes{instance=~"$instance", volume=~".:"}
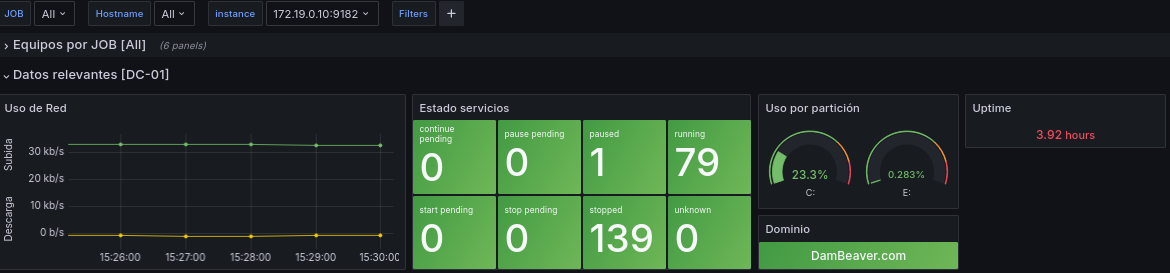
En estas querys modificaremos la referencia a la variable job por la variable instance, también modificaremos la visualización del estado de los servicios por un panel de stat y modificaremos la visualización de Uso de partición por un panel en gauge.
Añadiremos una visión del Uptime de la instance, con la query: avg(time() - windows_system_system_up_time{instance=~"$instance"}).
Añadiremos también que nos muestre el nombre del dominio de la instance con las transformaciones que vimos en el panel principal y con la siguiente query: windows_cs_hostname{instance=~"$instance"}
Quedando tal que así:
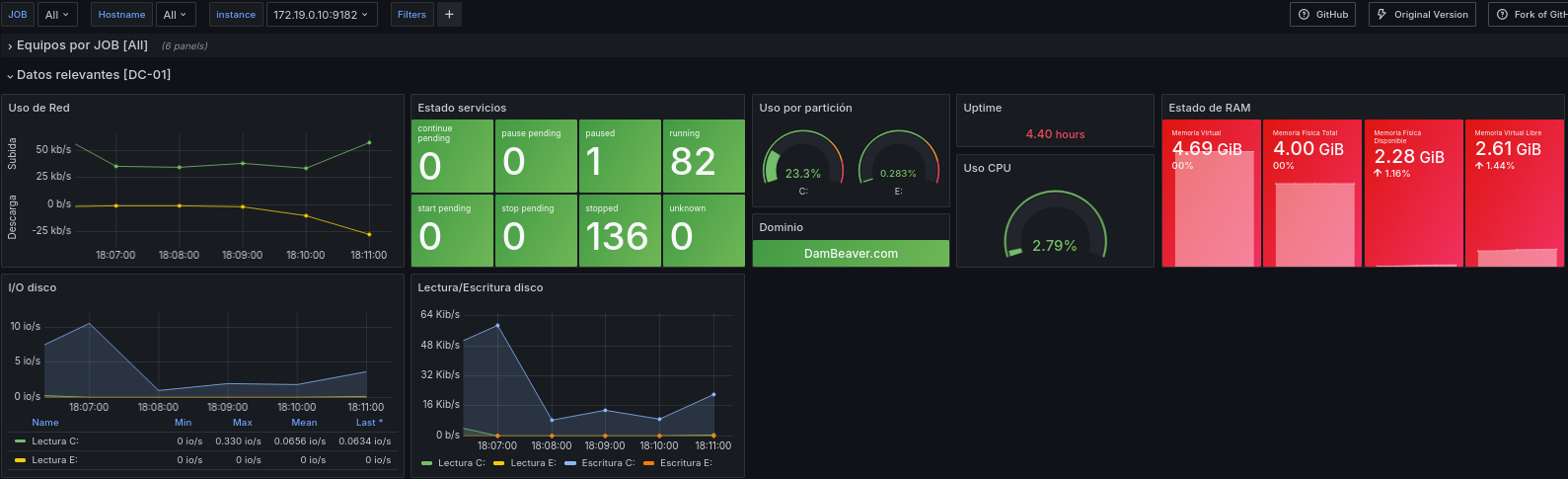
Añadiremos más paneles para controlar el uso de la CPU, los estados de la memoria RAM, I/O de disco, y Lectura/escritura de disco
Uso de la CPU (formato
Gauge): Query:100 - (avg(irate(windows_cpu_time_total{instance=~"$instance",mode="idle"}[2m])))*100- Estados memoria RAM (formato
stat): Querys:windows_os_virtual_memory_bytes{instance=~"$instance"}windows_cs_physical_memory_bytes{instance=~"$instance"}windows_os_physical_memory_free_bytes{instance=~"$instance"}windows_os_virtual_memory_free_bytes{instance=~"$instance"}
- I/O disco (formato
Time series): Querys:irate(windows_logical_disk_reads_total{instance=~"$instance", volume=~".:"}[5m])irate(windows_logical_disk_writes_total{instance=~"$instance", volume=~".:"}[5m])
- Lectura/Escritura disco (formato
Time series): Querys:irate(windows_logical_disk_read_bytes_total{instance=~"$instance", volume=~".:"}[5m])irate(windows_logical_disk_write_bytes_total{instance=~"$instance", volume=~".:"}[5m])
Tras estos cambios quedaría esta sección del dashboard tal que así:
Ahora añadiremos algunas métricas para controlar el estado del sistema, como los errores de red, el número de hilos del sistemas, o el número de excepciones del sistema:
- Errores de red: Querys:
irate(windows_net_packets_received_discarded_total{job=~"$job",instance=~"$instance", nic!~"(?i:(.*(isatap|VPN).*))"}[5m]) + irate(windows_net_packets_received_errors_total{job=~"$job",instance=~"$instance"}[5m])- irate(windows_net_packets_outbound_discarded_total{instance=~"$instance", nic!~"(?i:(.*(isatap|VPN).*))"}[5m]) + irate(windows_net_packets_outbound_errors_total{instance=~"$instance"}[5m])
- Threads: Query:
windows_system_threads{instance=~"$instance"}
- Excepciones: Query:
irate(windows_system_exception_dispatches_total{instance=~"$instance"}[5m])
Quedaría esta sección tal que así:
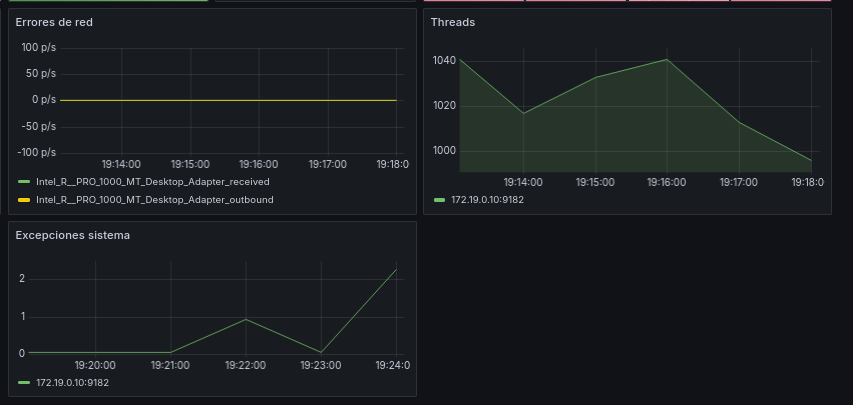
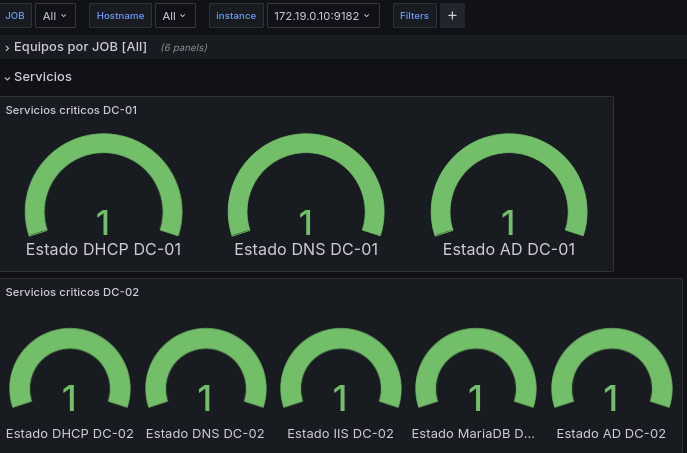
Ahora añadiremos algunos paneles para el control del servidor, controlaremos que los servicios como el DHCP, el DNS, la base de datos o el servicio IIS están funcionando correctamente.
Ya que este panel no será dependiente de la instance ni del job crearemos un nuevo row
Haremos querys personalizadas para cada servicio:
- DHCP DC-01: Query:
windows_service_state{name=~"dhcpserver",instance="172.19.0.10:9182",state="running"}
- DNS DC-01: Query:
windows_service_state{name=~"dns",instance="172.19.0.10:9182",state="running"}
- AD DC-01: Query:
windows_service_state{name="ntds",instance="172.19.0.10:9182",state="running"}
- DHCP DC-02: Query:
windows_service_state{name=~"dhcpserver",instance="172.19.0.11:9182",state="running"}
- DNS DC-02: Query:
windows_service_state{name=~"dns",instance="172.19.0.11:9182",state="running"}
- IIS DC-02: Query:
windows_service_state{name="w3svc",instance="172.19.0.11:9182",state="running"}
- MariaDB DC-02: Query:
- `windows_service_state{name=”mariadb”,instance=”172.19.0.11:9182”,state=”running”}
- AD DC-02: Query:
windows_service_state{name="ntds",instance="172.19.0.11:9182",state="running"}
Para su visualización estará en formato Gauge, y realizaremos las transformaciones vistas en el panel principal para su visualización.
Tendremos un resultado como este:
Y en caso de que algún servicio se detuviese, por ejemplo MariaDB:
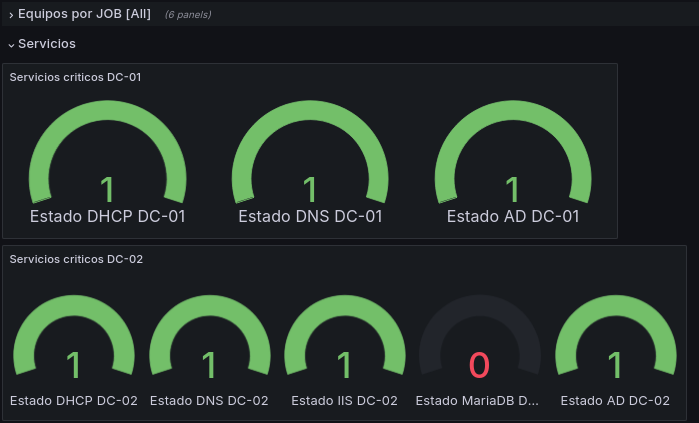
Con este habremos creado un Dashboard con el que podremos monitorizar de forma dinámica y bastante completa, así como la posibilidad de servir de guía para personas interesadas, pasaremos a las alertas, pero en caos de que se quiera probar este dashboard adjunto el código JSON para su creación Aquí